Use case walkthrough: A tour of Incident Management for DevOps users ►
This video steps through an example of how a DevOps engineer might use Incident Management to resolve an incident.
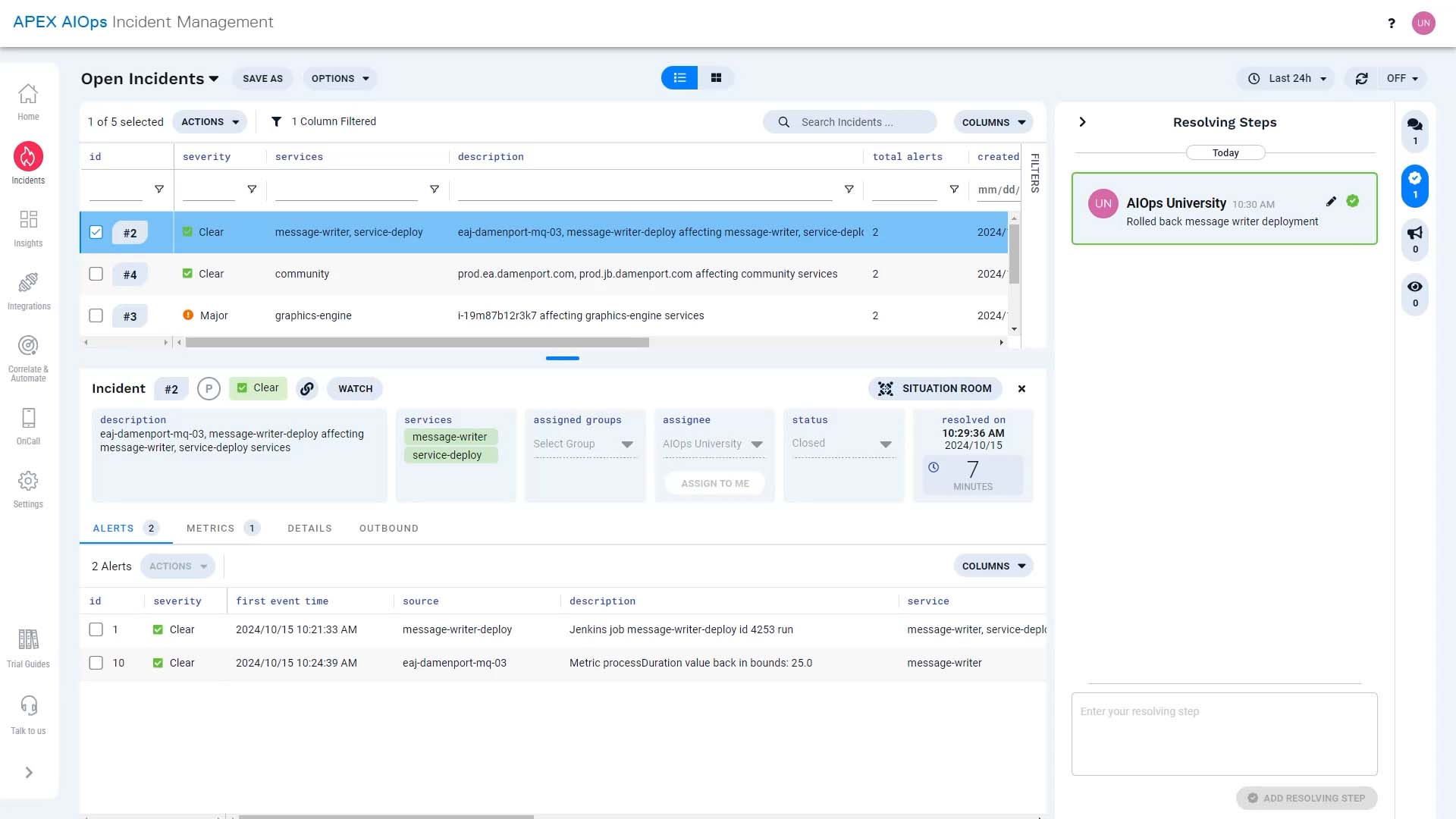
Let’s sample a day in the life of a DevOps engineer in Incident Management. This incident just came in. We are going to assign it to us and investigate.
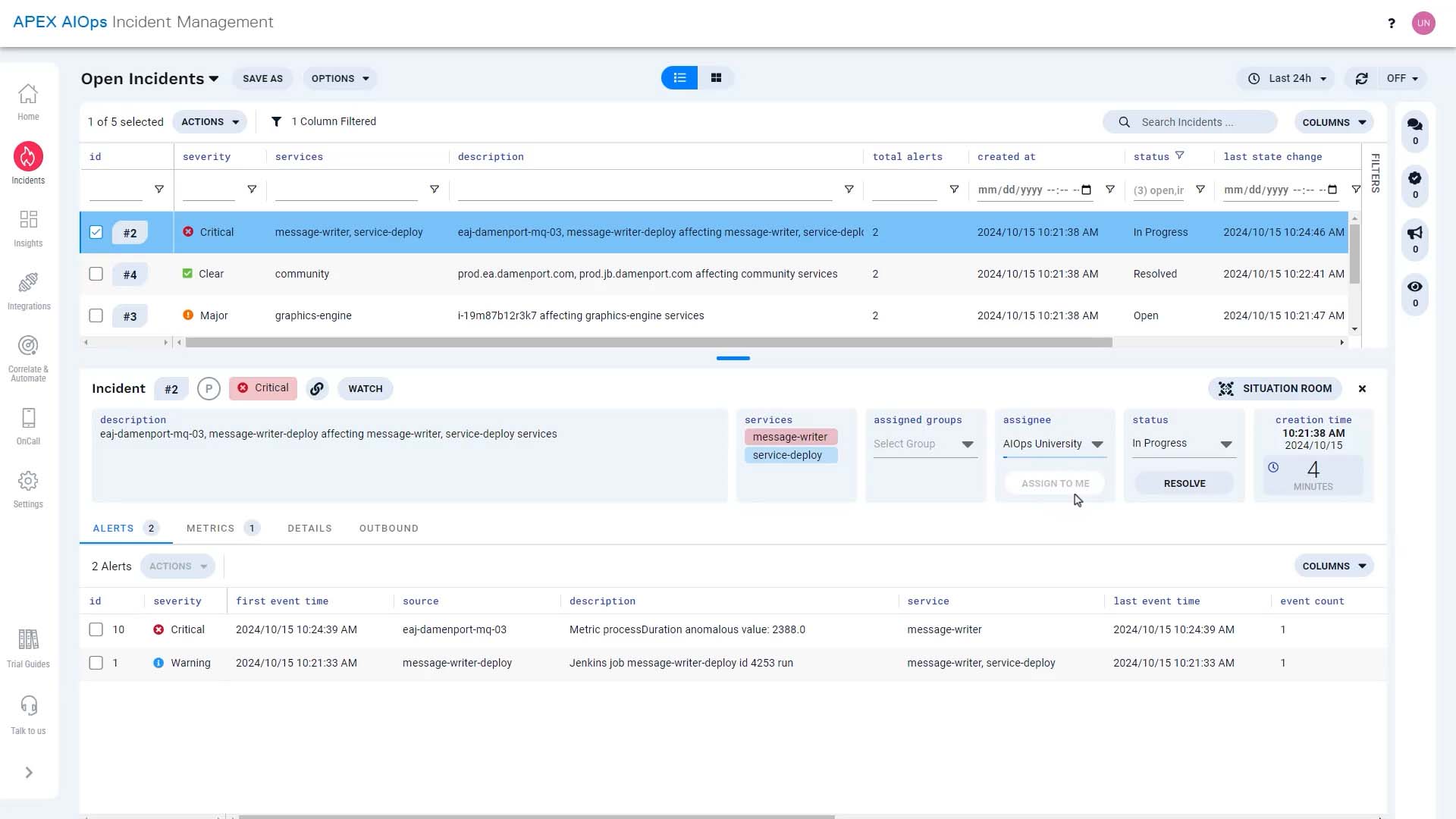
Let's go to the Situation Room for this incident. Judging from the description, the issue seems to be with the message writing service. Let’s take a look at the alerts that rolled up into this incident.
Let’s take a look at the alerts that rolled up into this incident. This is the first alert. The description says we just deployed an updated message writer service.
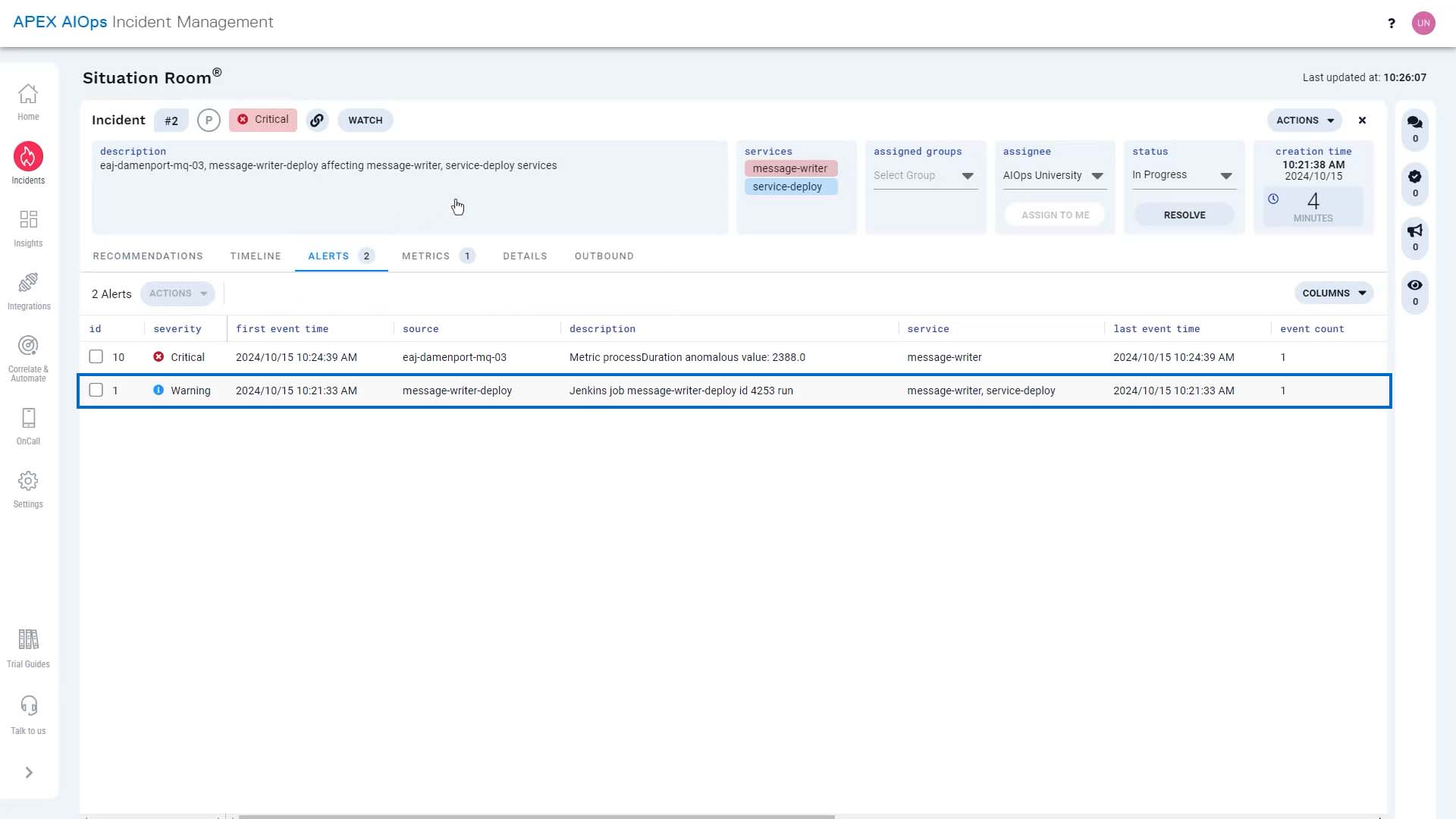
Then minutes later, the process duration metric went out of bounds to the critical state. So there seems to be a connection here.
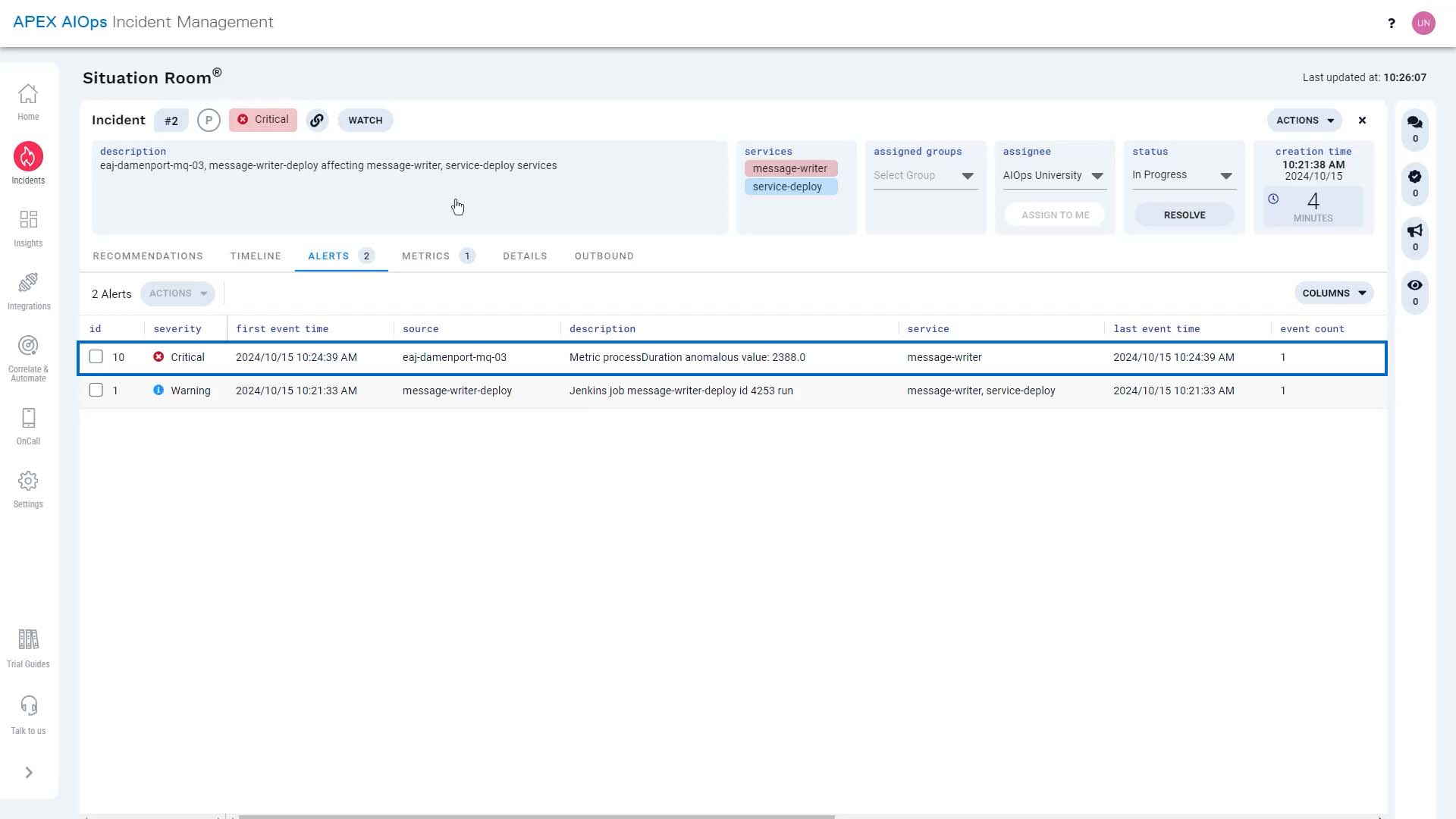
Let’s verify this connection by looking at the metrics. By default, the metrics screen is set to show the incident range, but we want to see it in the context of what’s normal.
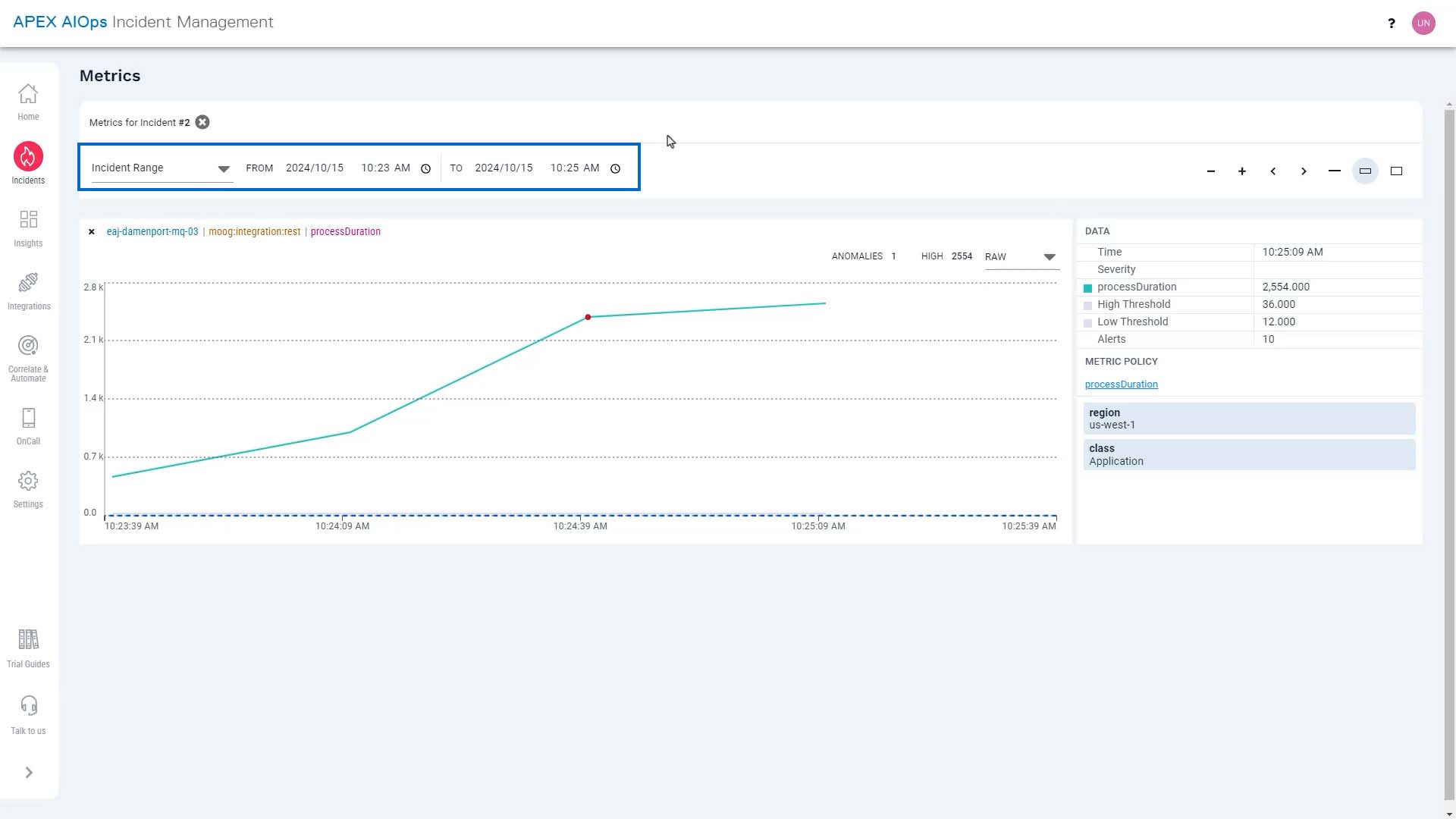
So we are going to zoom out a bit… and set the time range to the last half hour.
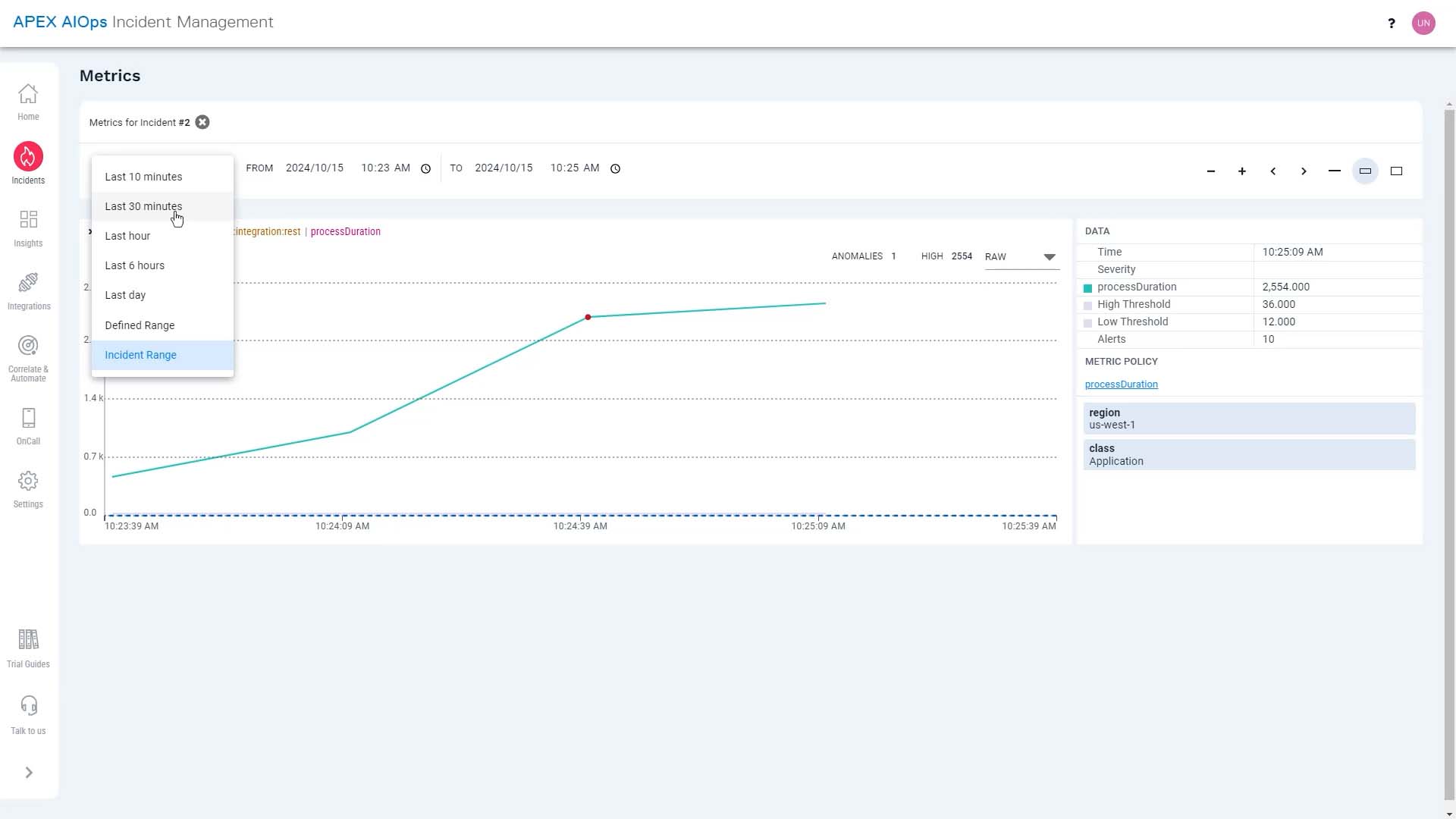
This is where the process duration metrics alert was triggered. Normally, it hardly takes 20 milliseconds to write anything to the database, and now it’s taking several seconds. That’s not good.
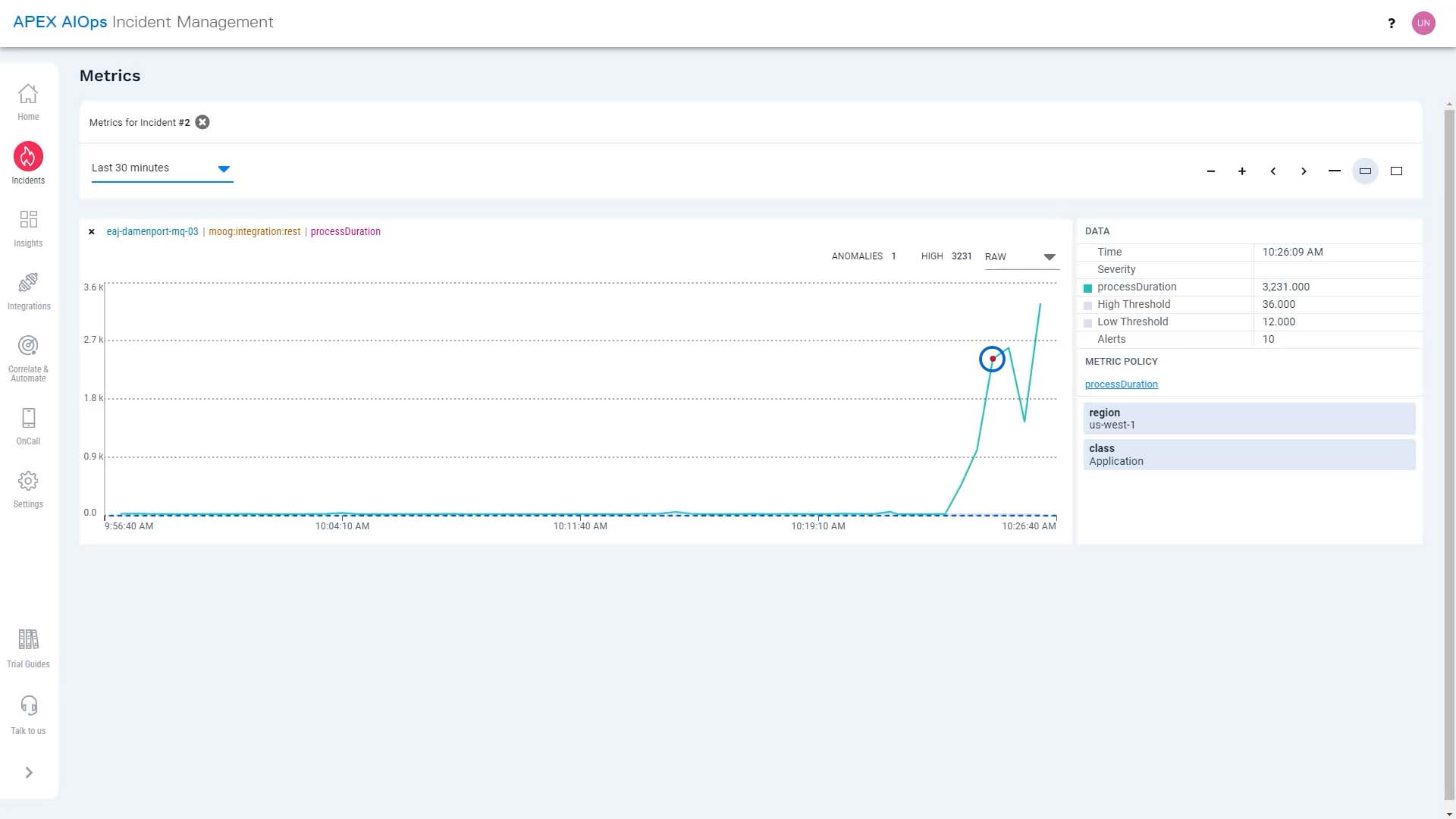
Now we have a choice- we could rollback the deployment and fix the issue in code that’s adding seconds to this process, or accept this as a new norm and have Incident Management learn it. For now, we are going to roll it back.
We rolled back the service update. And now a few minutes later, it looks like the metrics are back to normal. We’ll examine the message writing service and deploy an updated version when ready.
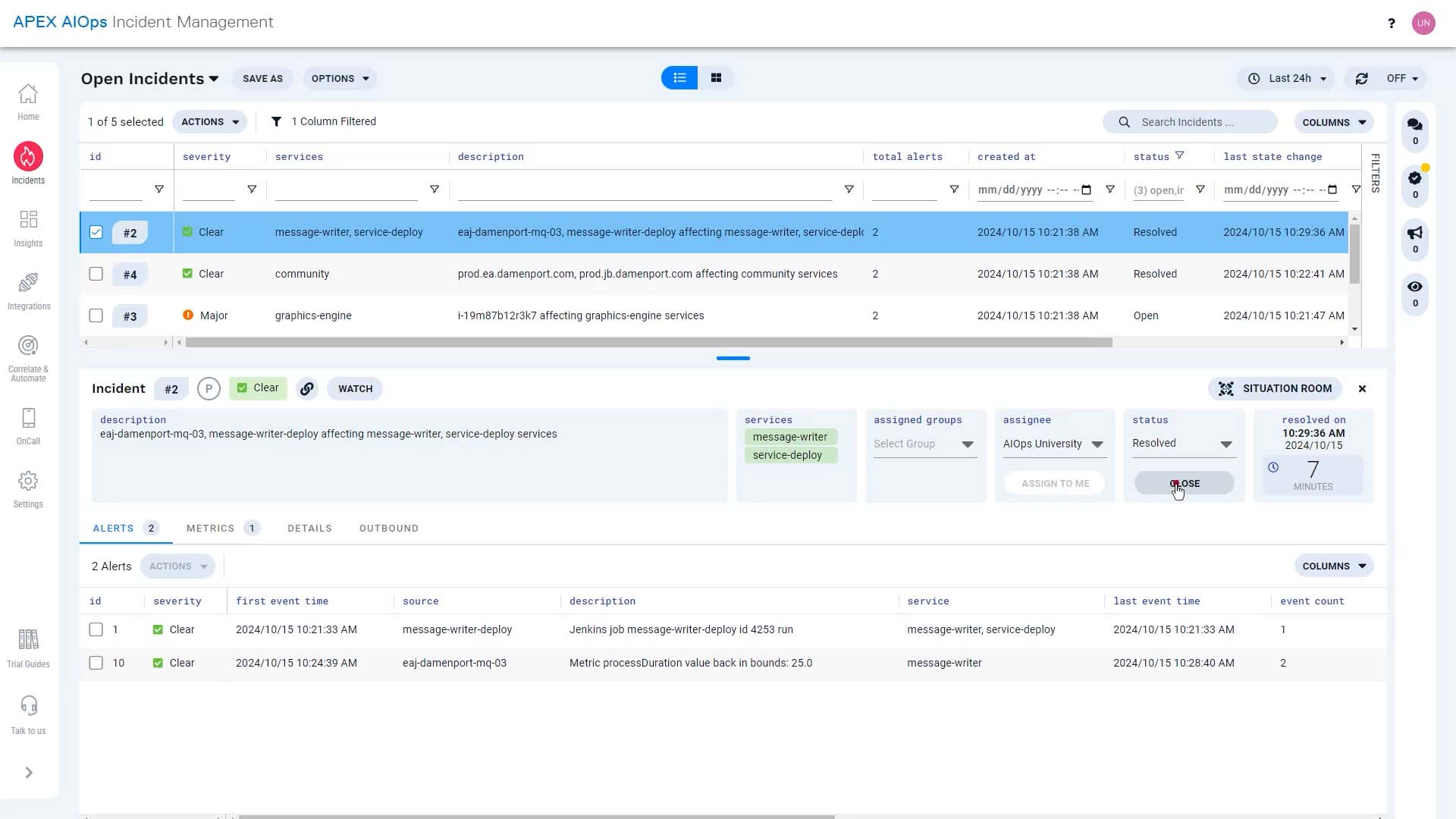
We are going to go back to the incident and close it. We’ll describe what we did to resolve the incident here, that way, Incident Management can suggest a solution for similar incidents in the future.
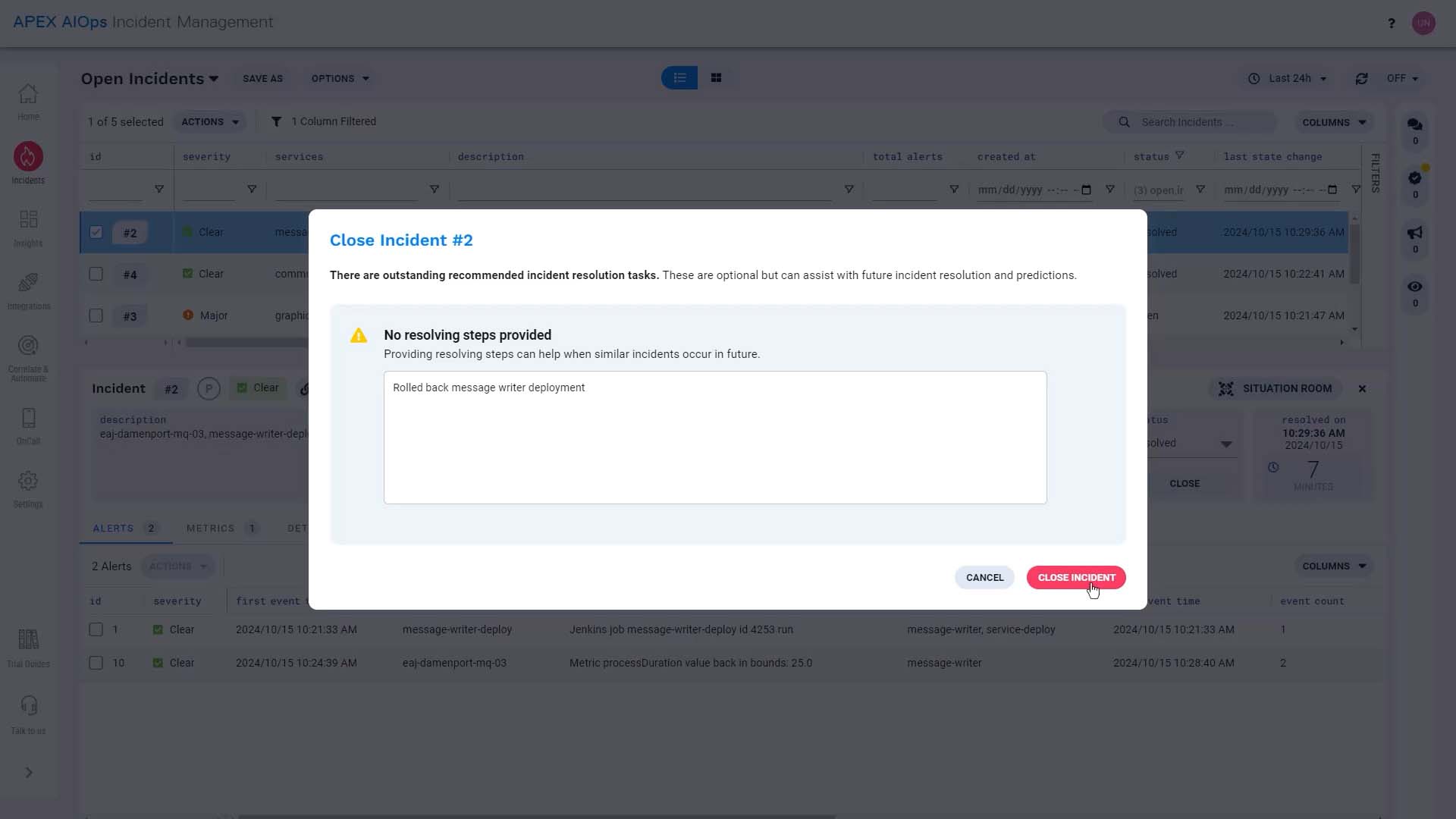
All set! Now you have seen a sample DevOps workflow in Incident Management. Thanks for watching!