Concept explainer: Algorithms vs rules in APEX AIOps Incident Management ►
This video explains the difference between Algorithms vs Rules in APEX AIOps Incident Management, and how Incident Management's correlation engine uses artificial intelligence and natural language processing to identify similar alerts.
*Please note Moogsoft is now part of Dell's IT Operations solution called APEX AIOps, and changed its name to APEX AIOps Incident Management. The UI in this video may differ slightly but the content covered is still relevant.
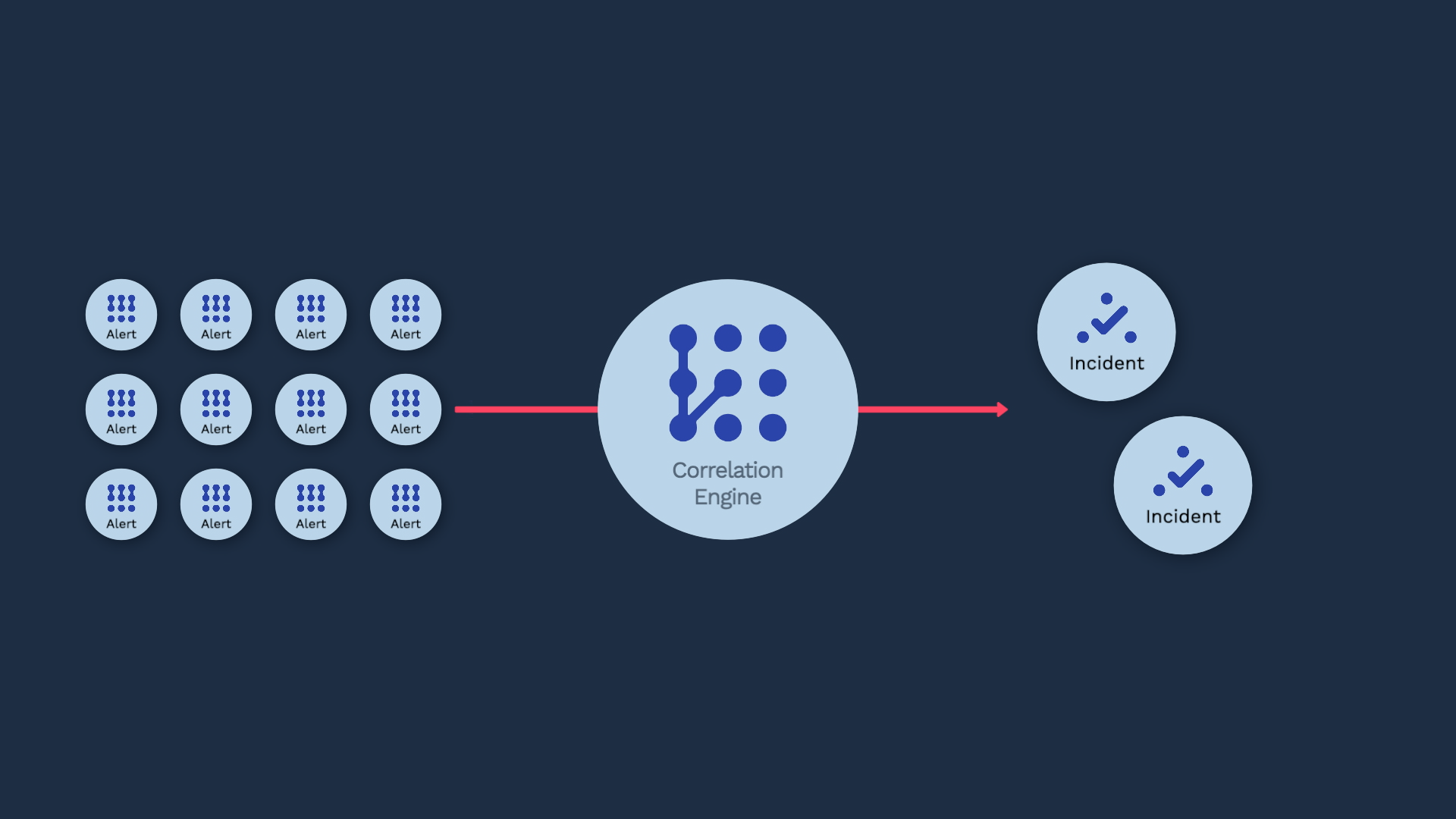
Incident Management’s correlation engine clusters alerts into incidents based on their relatedness. The way this works is fundamentally different from a rule-based categorization. In this video, you’ll learn exactly how.
Let’s use a really simple example. Suppose our company has retail locations all over the country, and we want to group issues by location of the shops. We’ll start with an easy one - what if two alerts had identical address information. It’s easy to write a rule that includes one conditional statement to detect this.

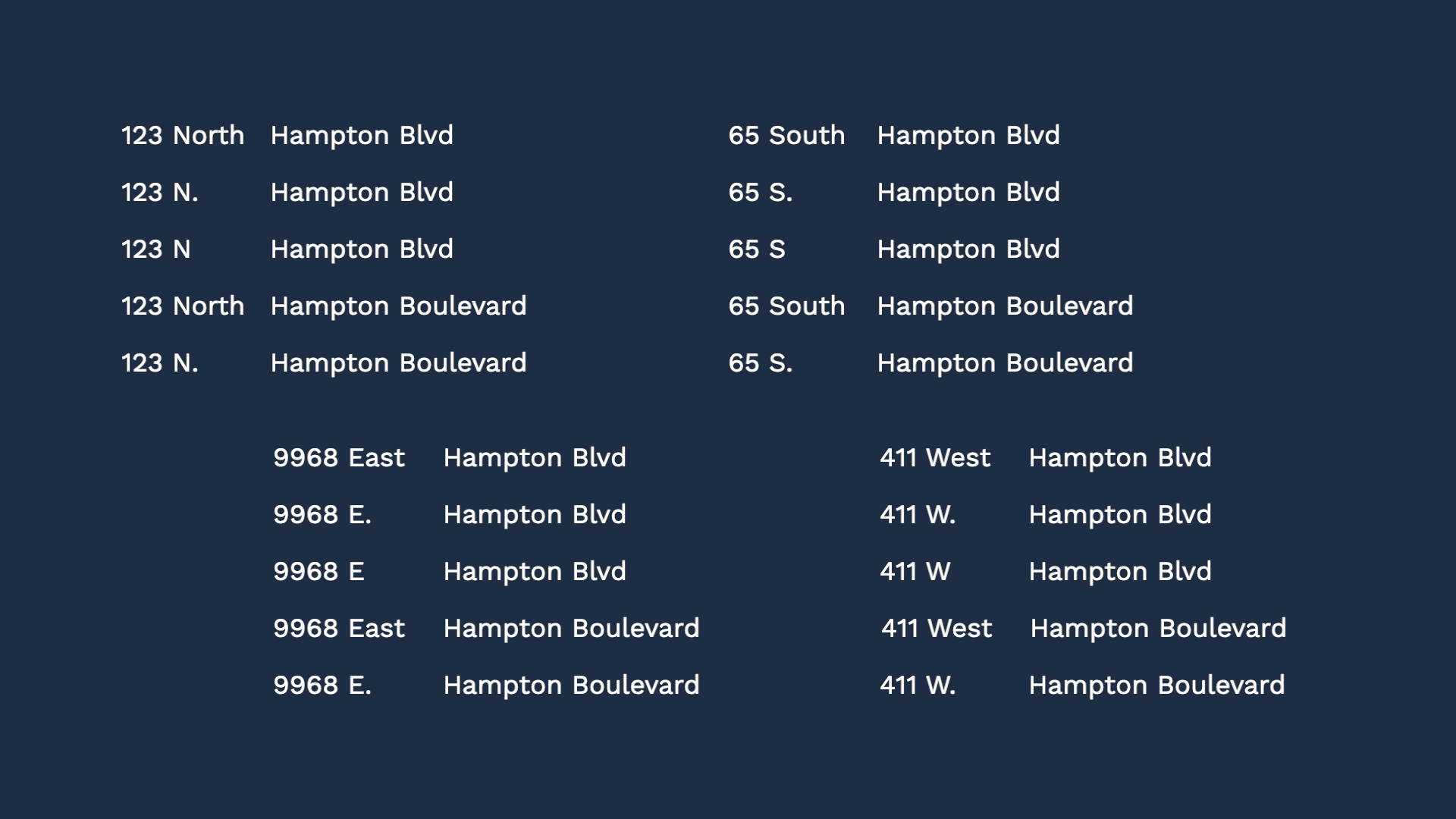
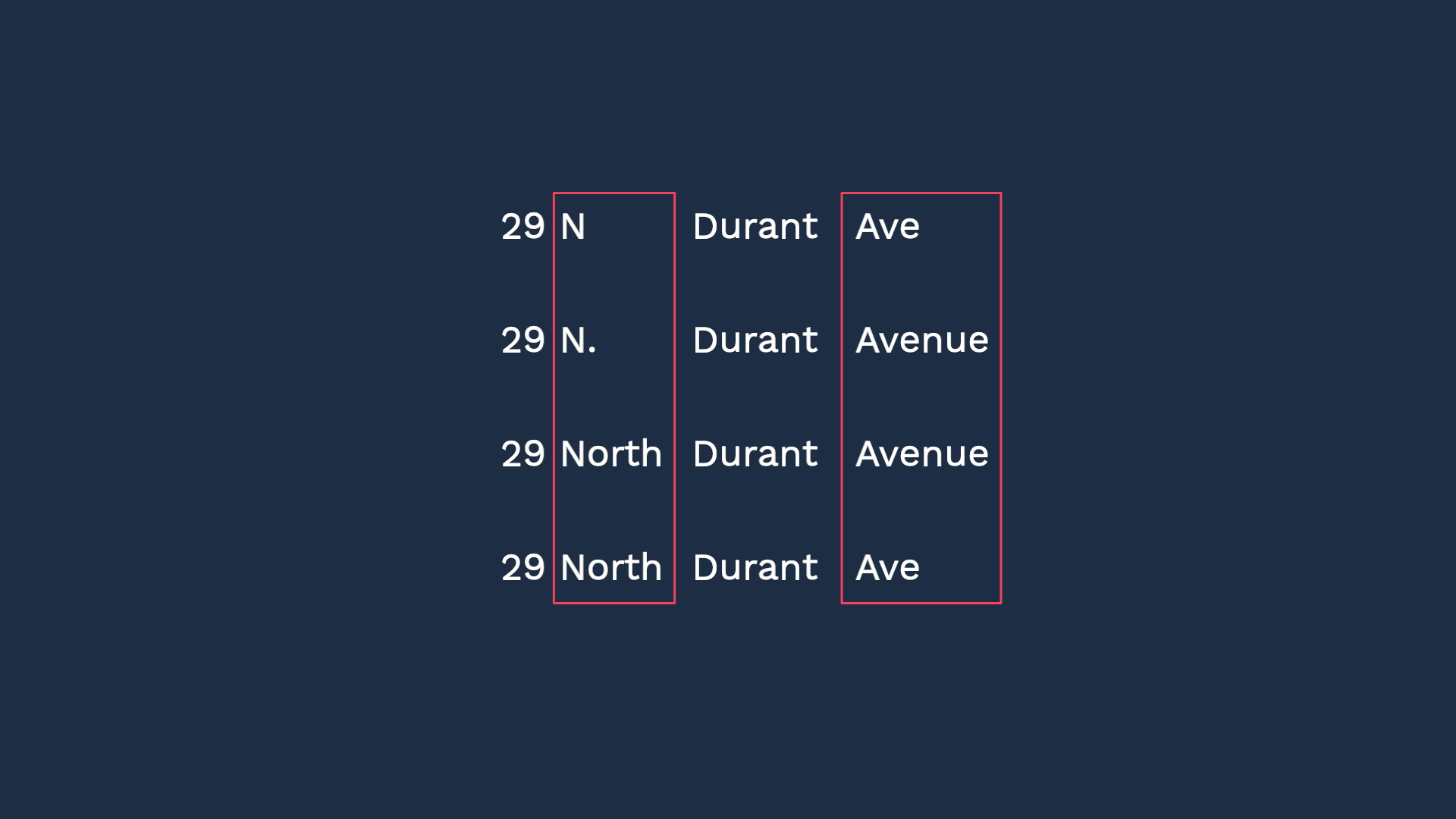
But our environment is not that uniform. For example, you may have multiple source monitoring systems, and each one may use a slightly different naming convention. Further, even within one system, some administrators may not be so careful about consistency. So what If the events came from these 5 different addresses? To the human eye, it’s easy to determine they all point to the same place, but...

To recognize all these variations, we need to set up a rule to recognize N, N., and North as the same thing. Then do the same with “blvd”, and “boulevard."

But then, here’s another store address that’s very similar.

While we are at it, we should take care of the shops on the East and West Hampton blvd, too.
We’ve got to write rules to make sure all of these variations are recognized as the same address while making sure we don’t mix up these 4 stores.
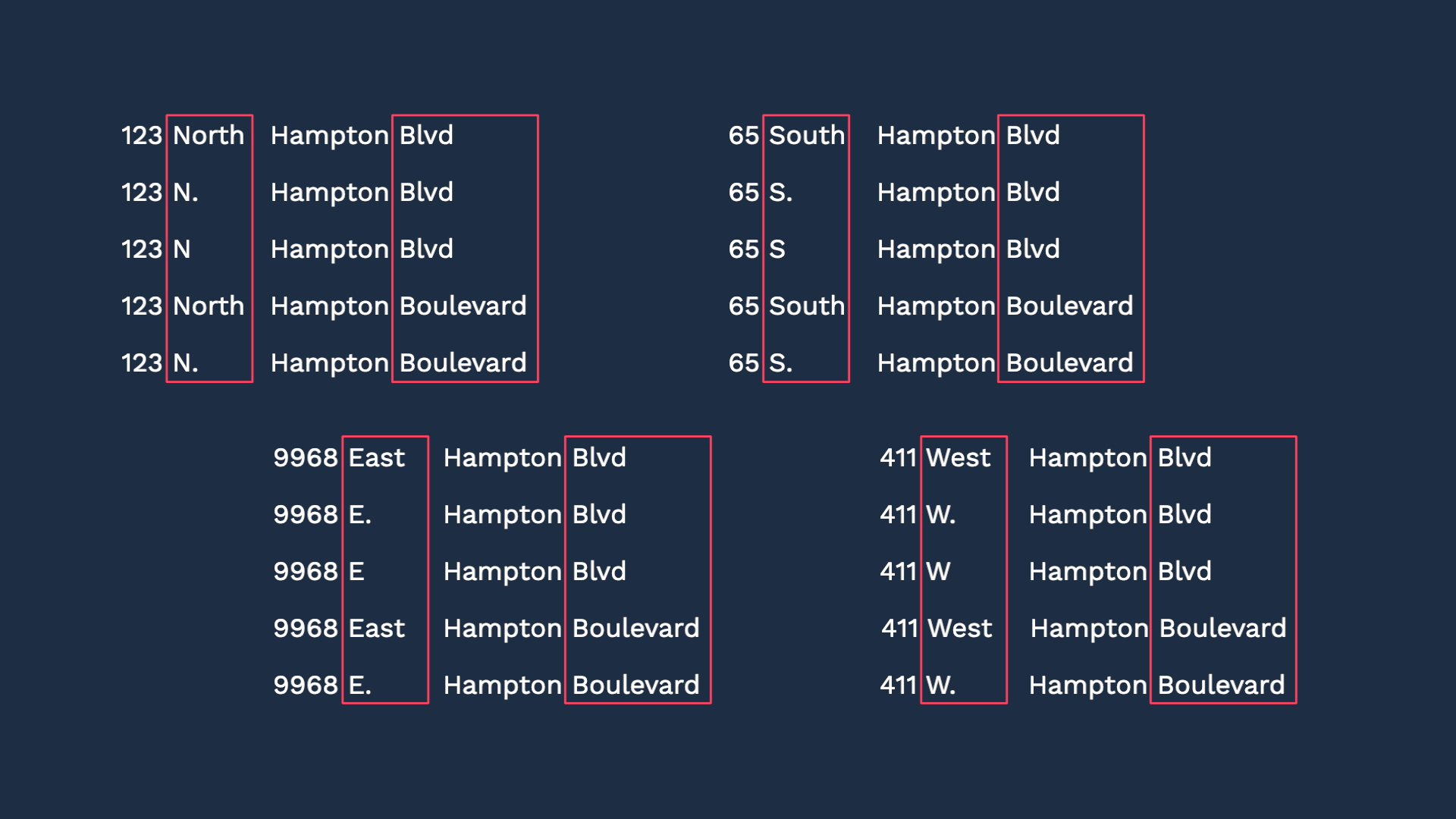
What’s so obvious to the human eye and brain often takes a lot of IF - THENs.
Incident Management’s correlation engine can identify the similarity of these items while differentiating where needed.

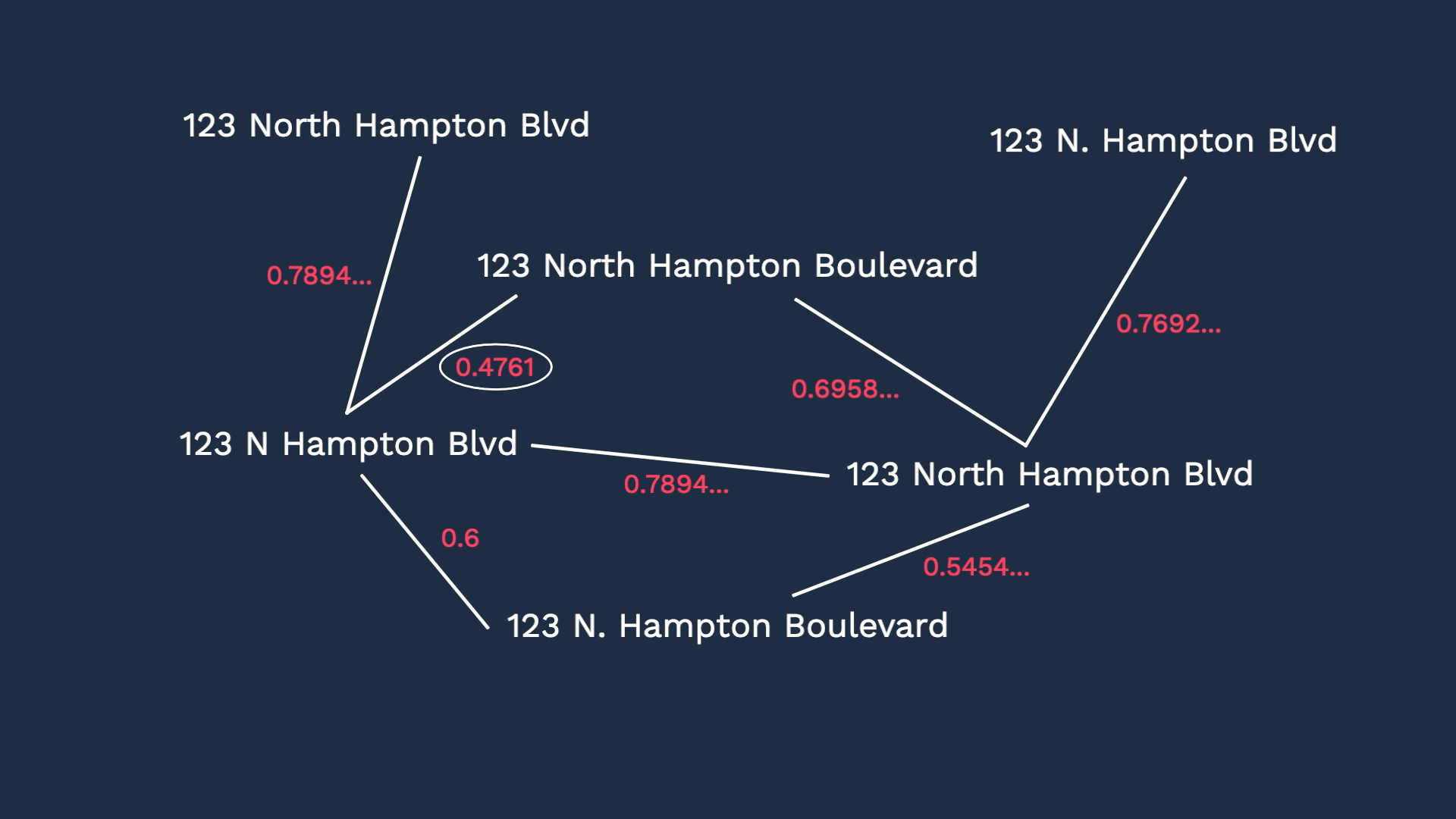
This example uses the technique called shingle size to calculate similarity,

These two variations are 86% similar.

In the same manner, the similarity at the shingle level can be calculated between all variations. In this example, looks like the lowest score is around 48%
Now, if you calculate the similarity score in the same manner between this shop and this shop, we got 34% similarity.
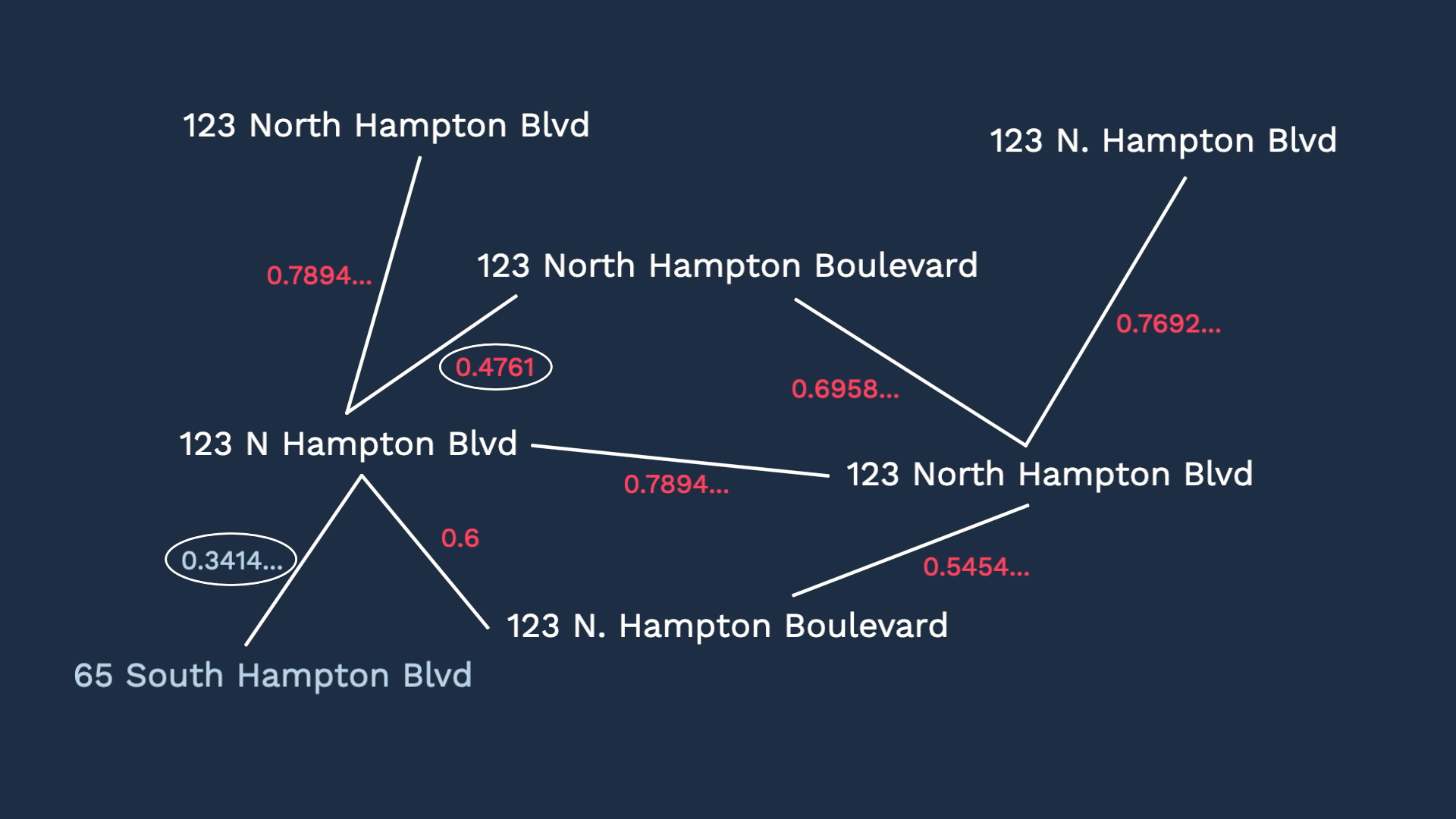
So now, instead of writing so many rules to bundle the alerts, we need to set up one cookbook recipe to achieve the same result.
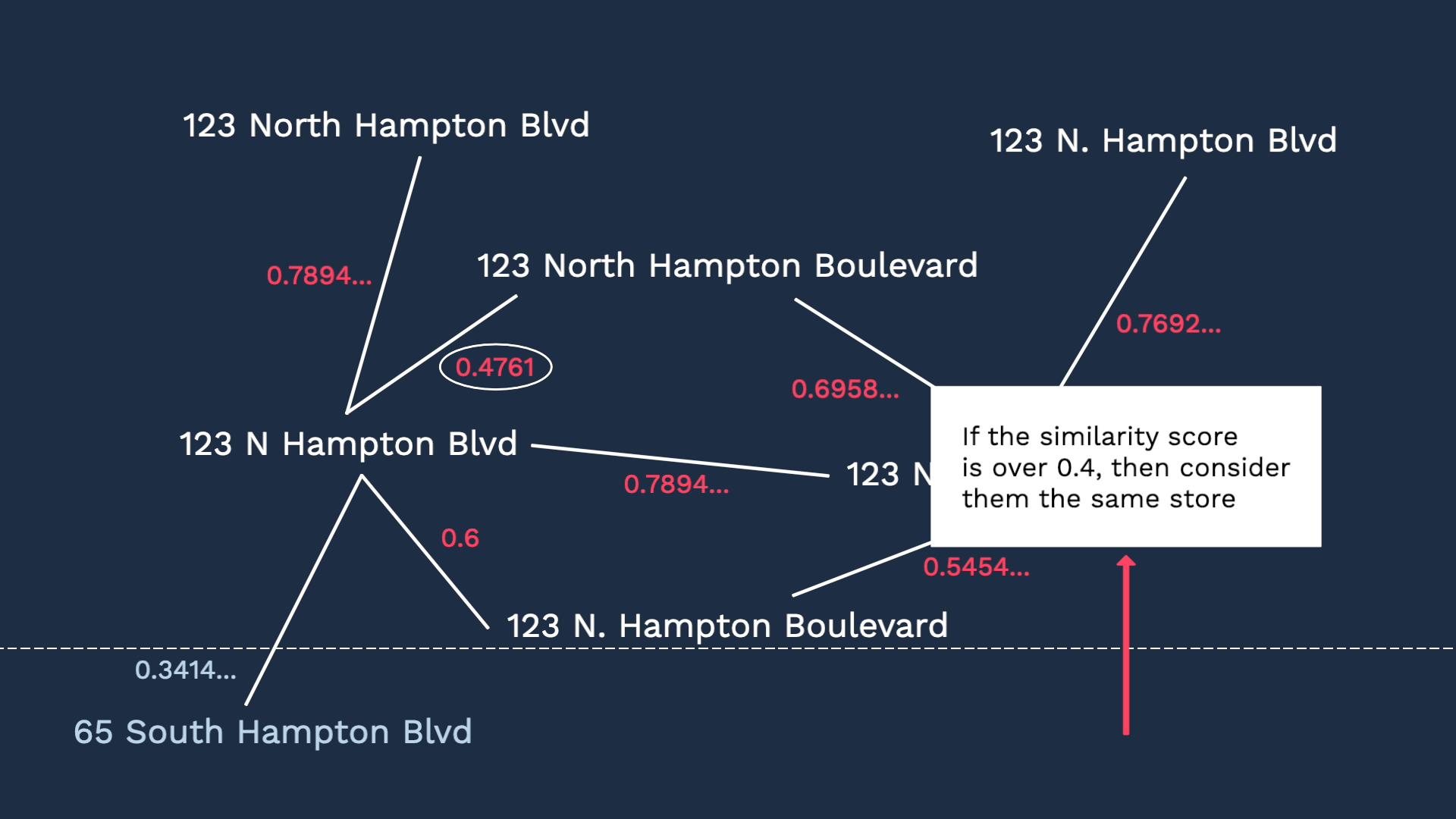
Moreover, our correlation engine’s high adaptability keeps the maintenance effort low, too. Let’s say we opened up new stores. If we are writing rules, then we need to add another set of rules to make sure the events in these shops are bundled together.
Or some shops may close. Then you have rules that are no longer useful.

With the correlation engine, the same definition can handle the new cases with no extra work.
So, now you know how Incident Management’s correlation engines are different from the rules. Hope you are excited about not having to maintain thousands of rules.
Thanks for watching!