Use case walkthrough: Deduplicate events to reduce noise ►
A busy service with multiple monitors can generate a flood of metrics, anomalies, and events. One issue might trigger a large number of repeat and duplicate events. APEX AIOps Incident Management analyzes every new piece of data — What is this? When did it happen? What is its severity? How often has it happened before? — and aggregates events for the same issue into alerts. Whenever it adds a new event, Incident Management updates the alert fields — event count, last event time, severity — so the alert always contains the latest information about the underlying issue. This process removes the duplicate, repeat, and obsolete noise from the data stream.
*Please note Moogsoft is now part of Dell's IT Operations solution called APEX AIOps, and changed its name to APEX AIOps Incident Management. The UI in this video may differ slightly but the content covered is still relevant.
One of the benefits of implementing Incident Management is that you can reduce noise, and focus on what matters. In this video, we’ll take a look at the noise reduction mechanism, using sample data from the real world.
We’ve extracted this sample data from an actual monitoring environment. The data is anonymized, but the events are real.
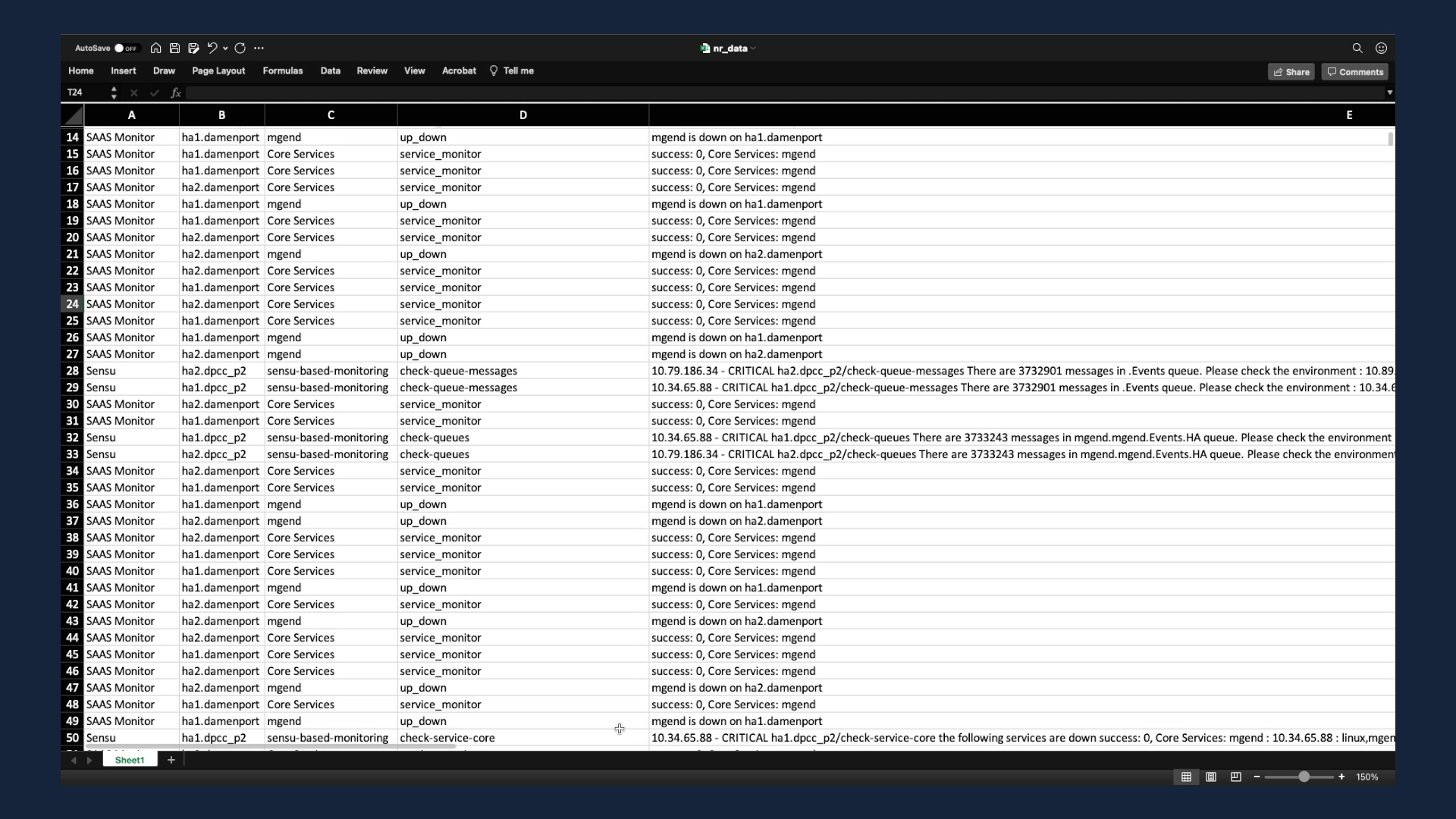
The event data is coming from three different sources: Cloudwatch, a home grown monitoring tool, and Sensu. These three tools have been monitoring a SaaS applications environment.
Here we’ve got about 1700 events. Let’s feed this to Incident Management and see what happens.
Incident Management deduplicates events and forms alerts. For example, this event indicates disk i/o is very high for this.dpcc_p2 server. Then, here comes another event to tell you the condition has worsened.
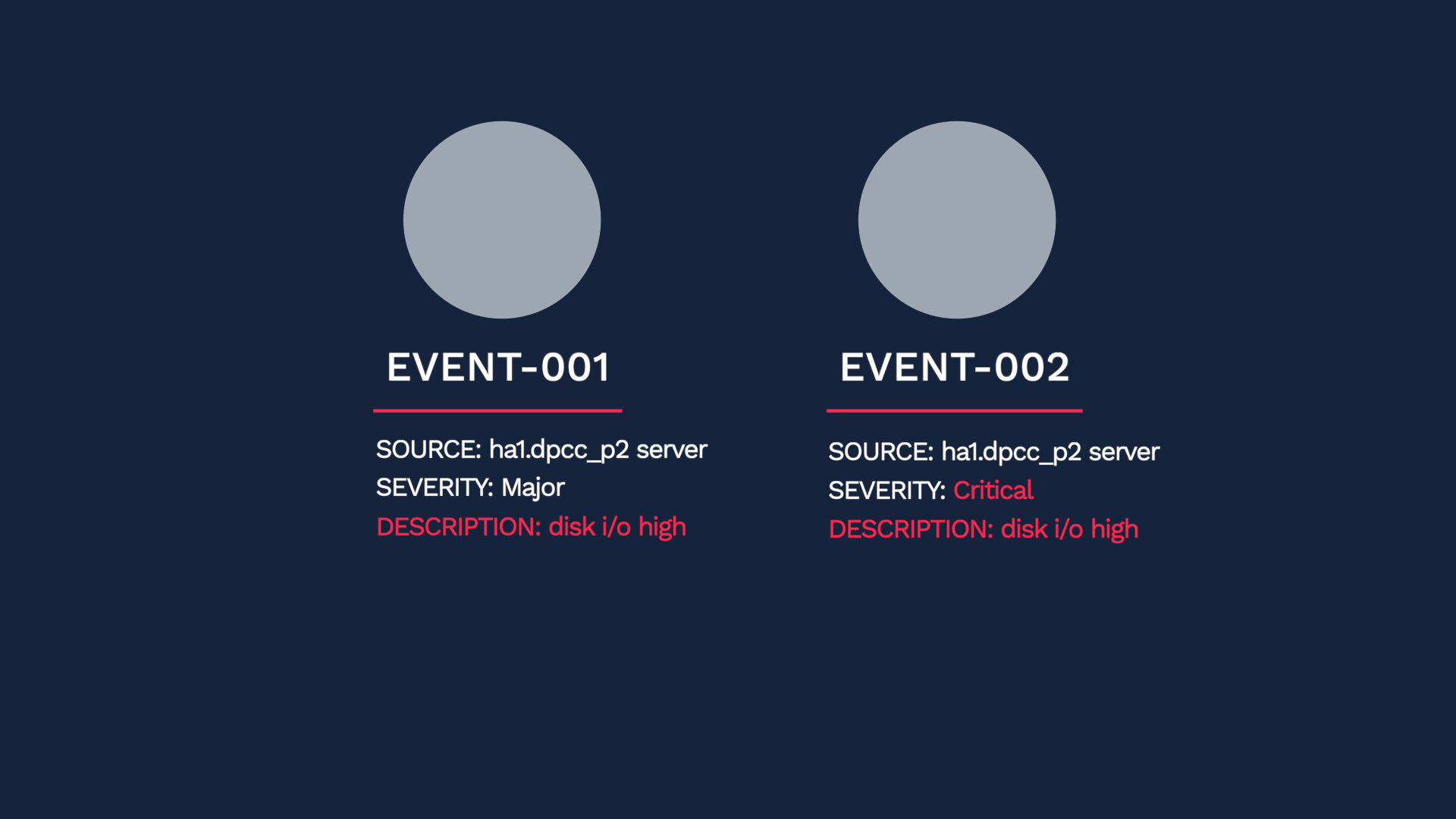
These should not be considered separate problems, so Incident Management de-duplicates them into one alert.

Let’s take a closer look. How exactly do we determine an event to be a duplicate?
In short, Incident Management compares the dedupe_key values of the two events, and if they are a 100% match, the two events are deduplicated into one alert. The dedupe_key value is a combination of the Source, Class, and Check fields in an event. If the incoming event is using the service field, that value is used also.

In this example, instead of two events, you now have one alert in the critical state. Because of the deduplication, you will not be allocating separate resources to each event, and you will have more context for troubleshooting.

Now consider this case: After the critical event, another event arrives with the same dedupe key value. But this time, the severity value of the event is Clear. Maybe an automated runbook kicked in and addressed the issue.

Incident Management dedupes this event into an existing alert. The status of the alert updates to Clear.

Without deduplication, it would take a manual correlation to figure out the issue has resolved itself. Have you had a series of link flapping events? All those up and down events would be consolidated into one alert with Incident Management.
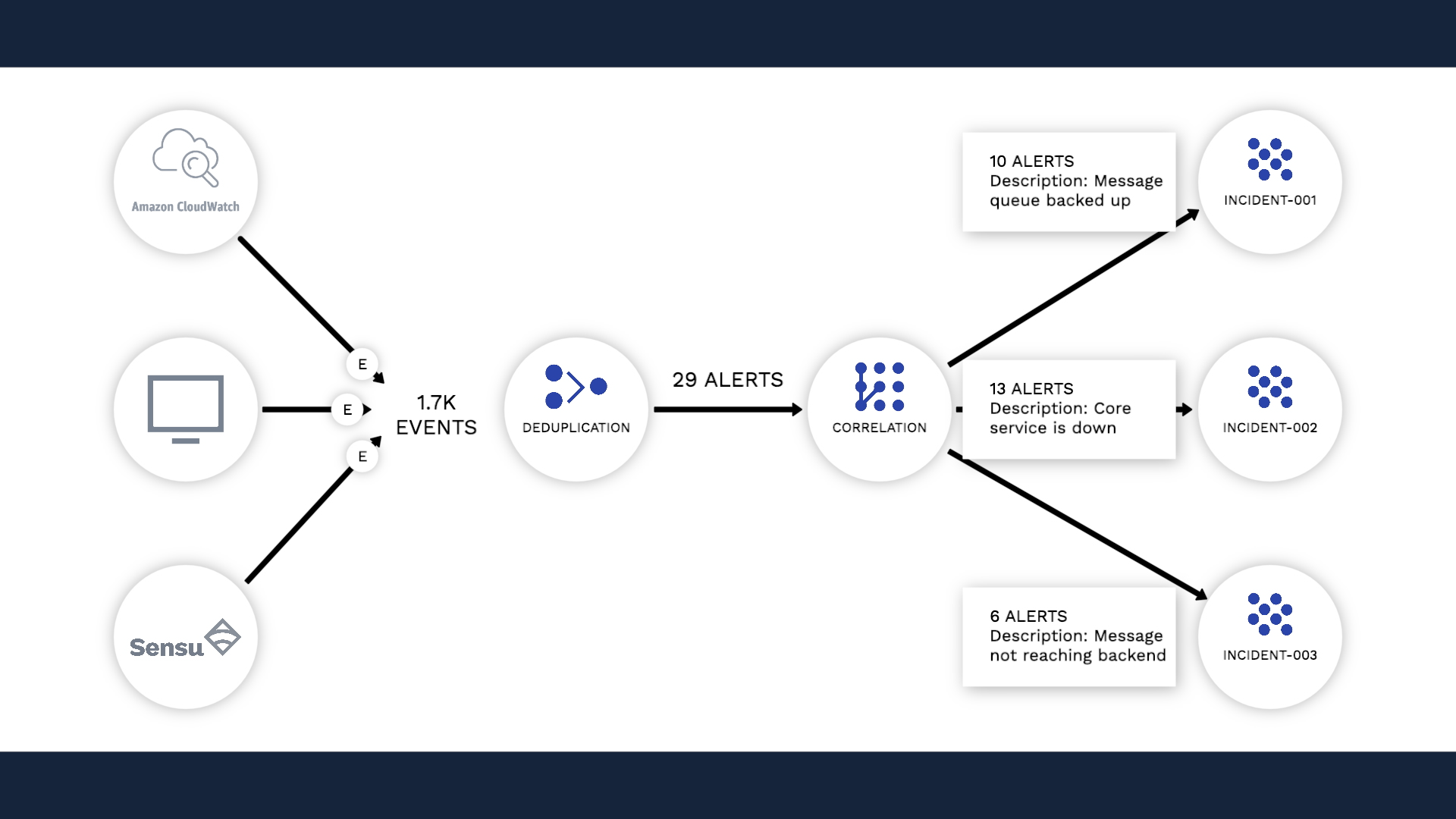
So, after the 1700 events have been processed, here’s what we got. They are deduplicated into 29 alerts.
This is the power of noise reduction. It helps you direct your focus on what actually matters.
But we don’t stop here. These 29 alerts are processed further before you come in. They are now correlated based on their relatedness.
Here, the 29 alerts are now clustered into 3 incidents.
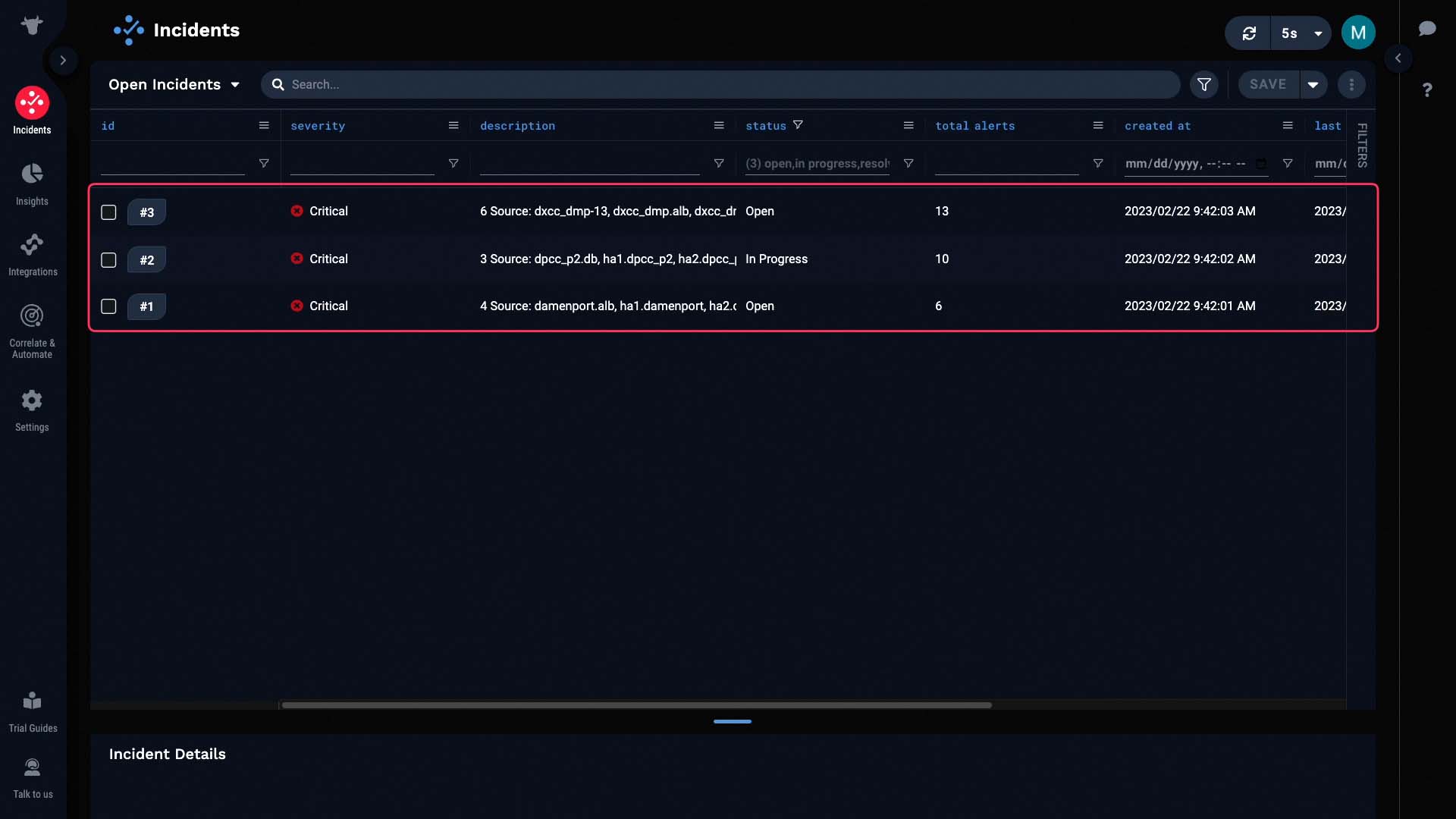
Incident Management evaluates alerts for their relatedness, and clusters the related alerts into one incident.To learn more about the correlation mechanism, watch the “Correlation Engine in APEX AIOps Incident Management” video.

Imagine instead of getting paged 29 times for each of the alerts, now you get 3. No more pager fatigue for your team!

Let’s examine one of the incidents and verify Incident Management has made a meaningful correlation. Let’s see if we can figure out what’s going on with this incident. Let’s go into the Situation Room. The Situation Room is where you can collaborate with your team on an incident.
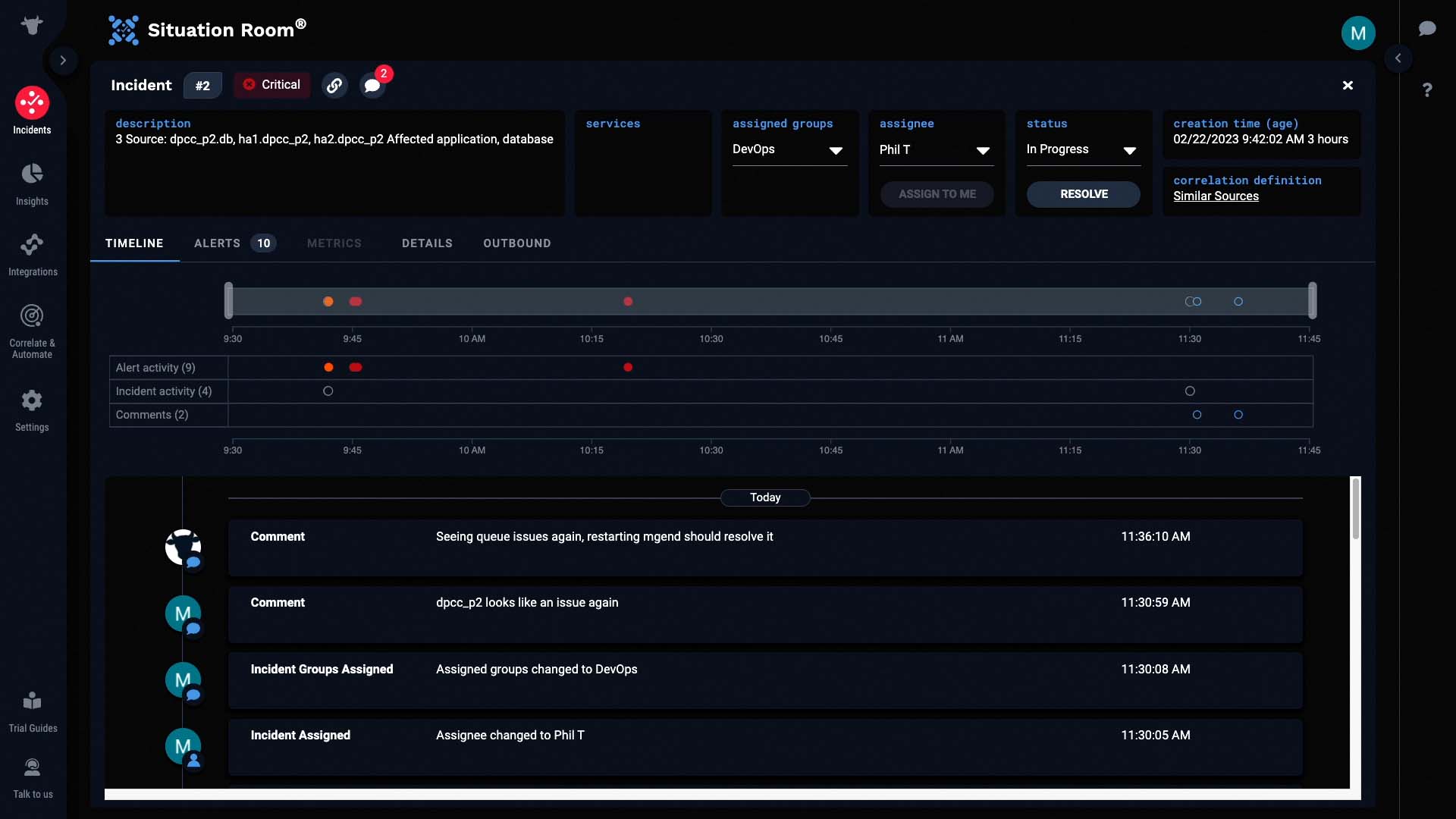
Looks like a team is already assigned to this one.
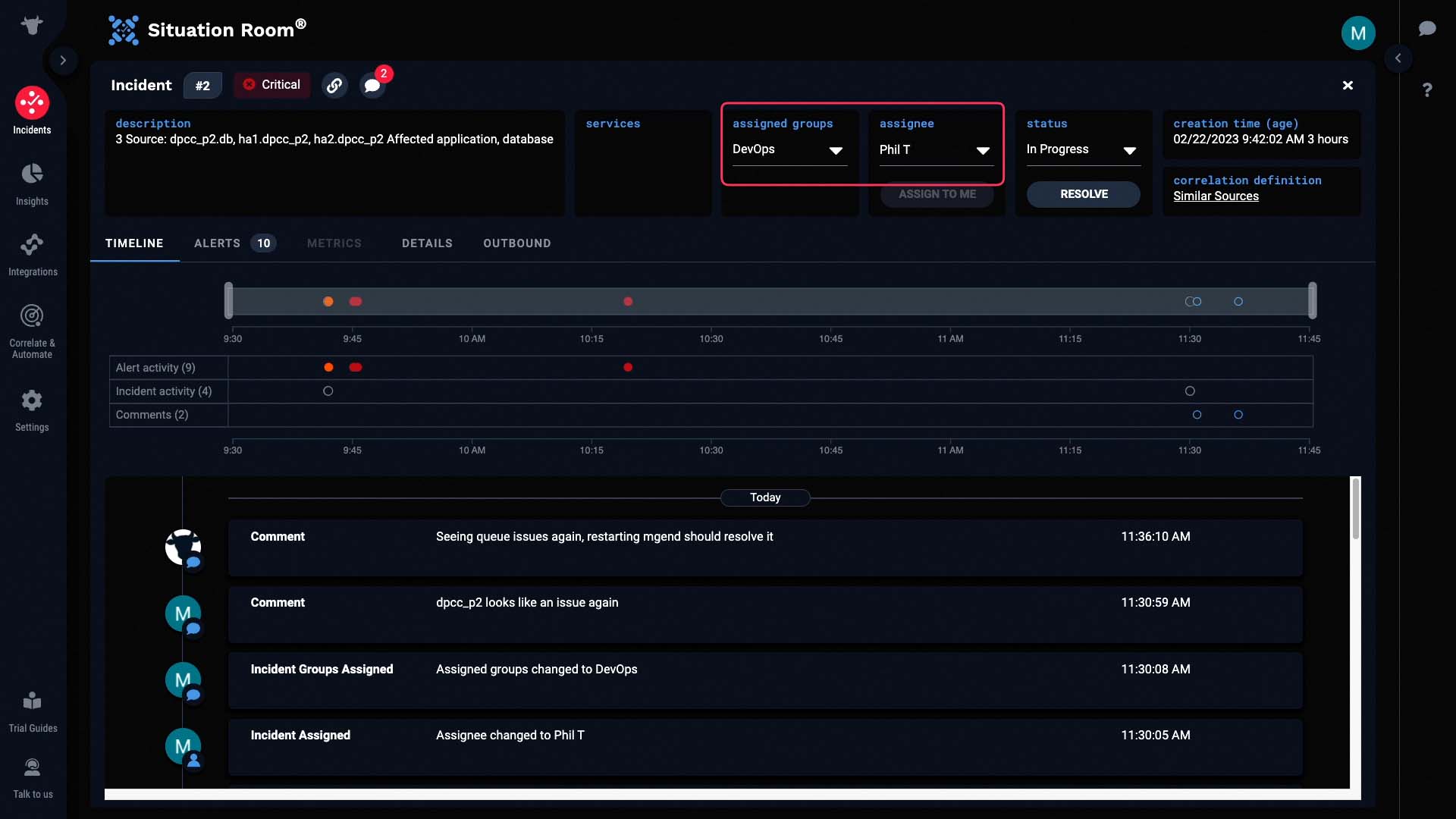
Here, we can see the timeline of activities pertaining to this incident.
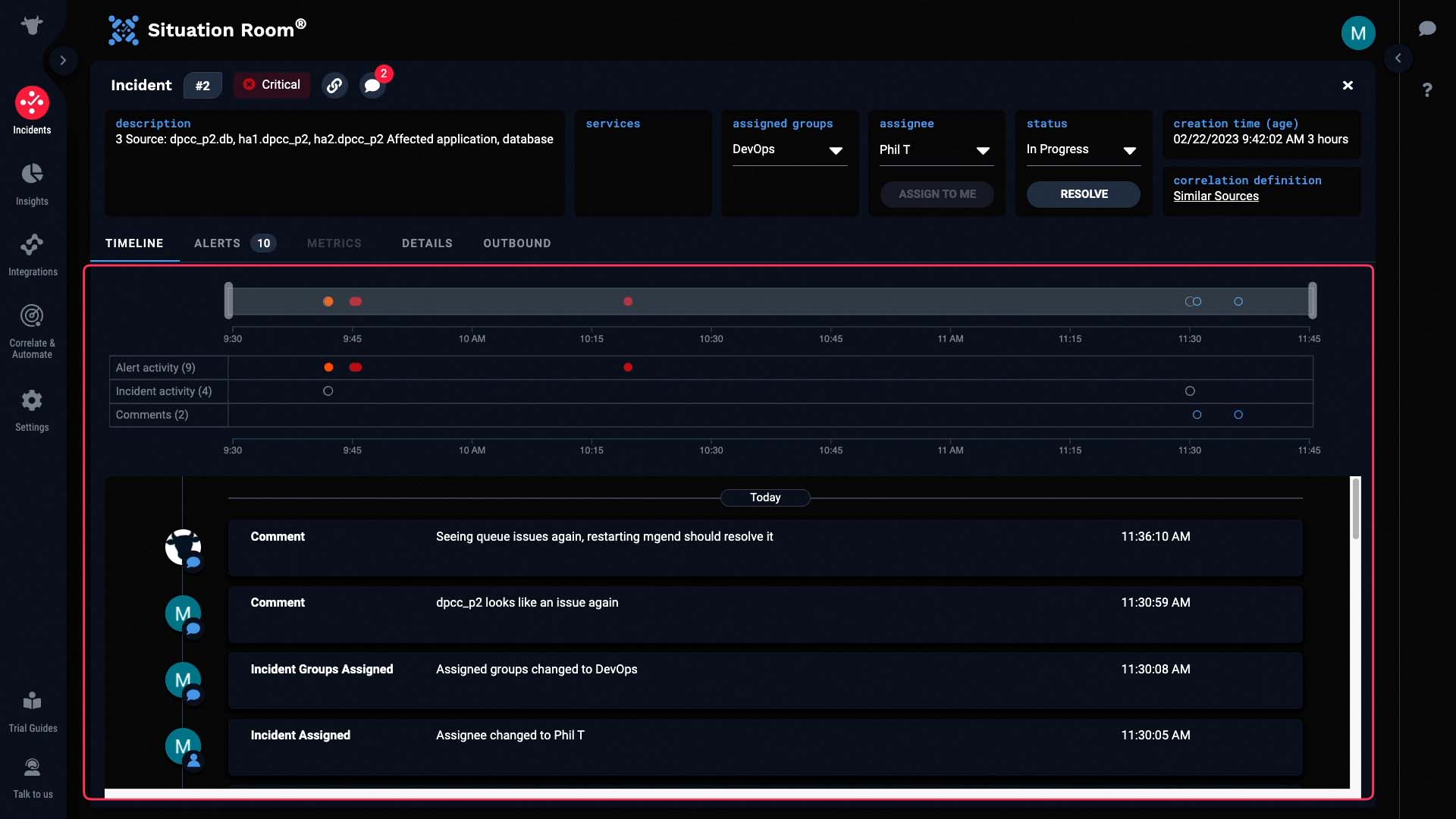
We can zoom in to any particular area of interest to filter the activities.
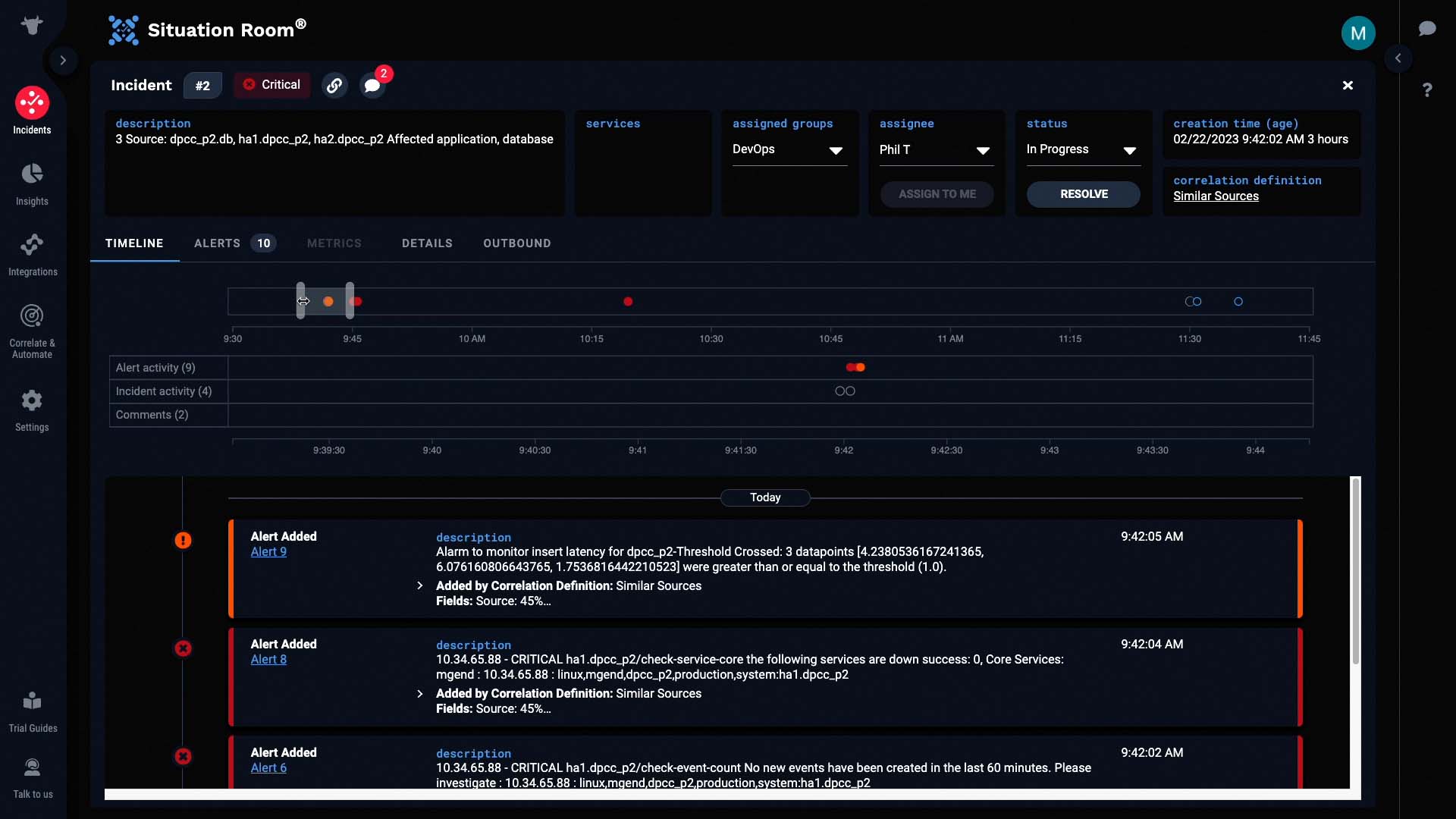
Looks like the group assigned is already reviewing this incident. Let’s do the same!
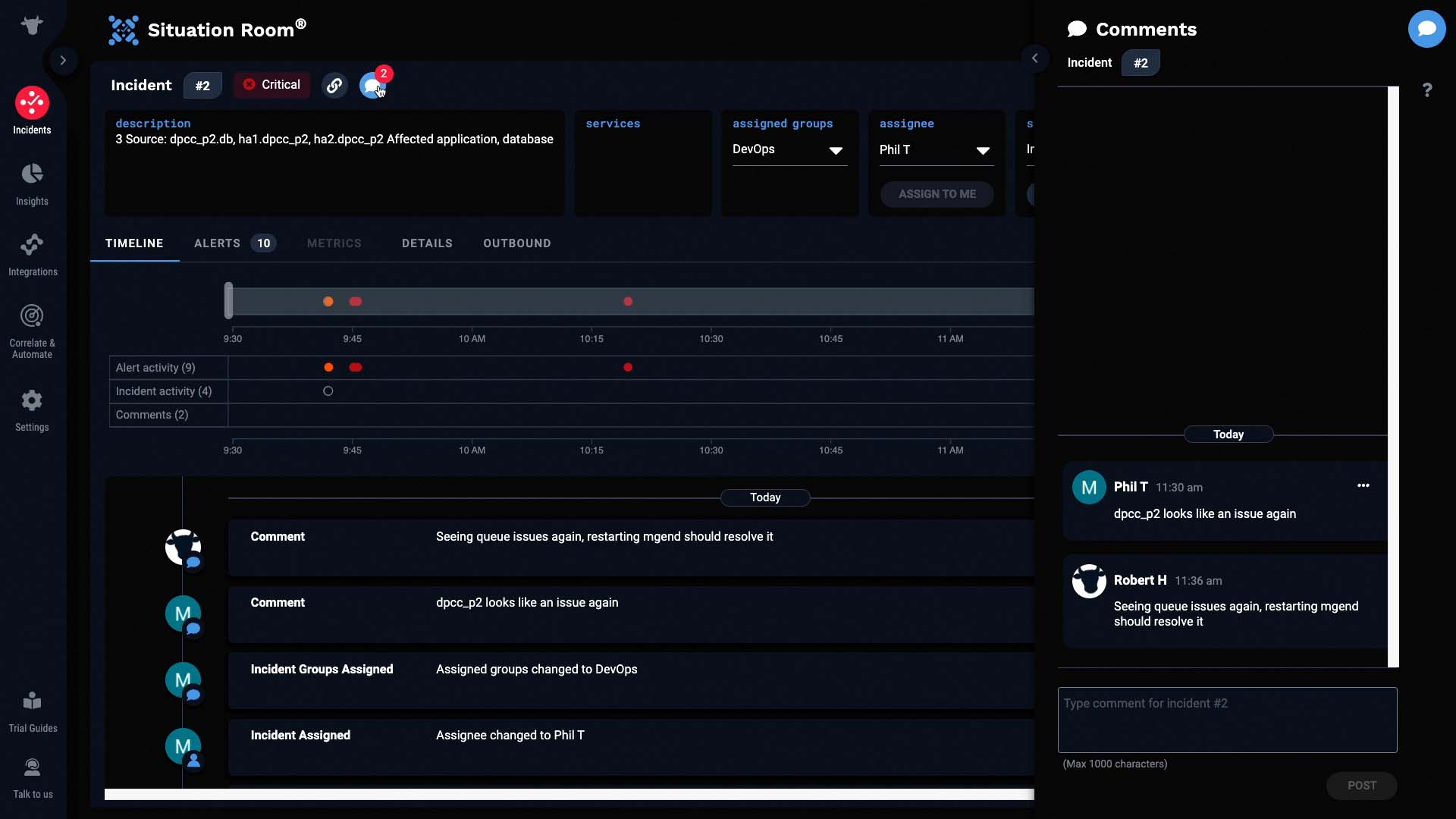
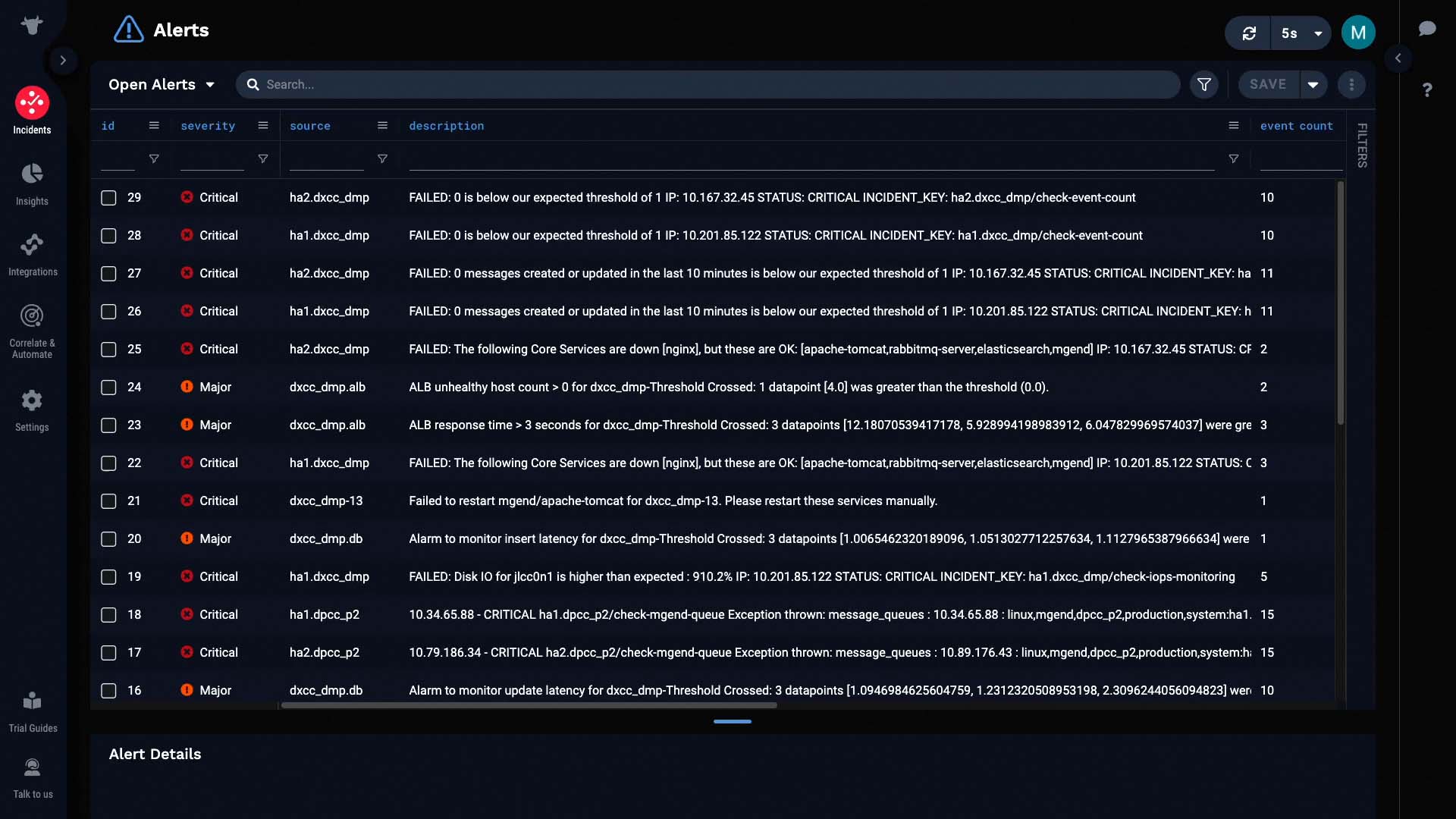
We’ll look at the alerts in the incident. The incident has 10 alerts, which consist of 169 events.
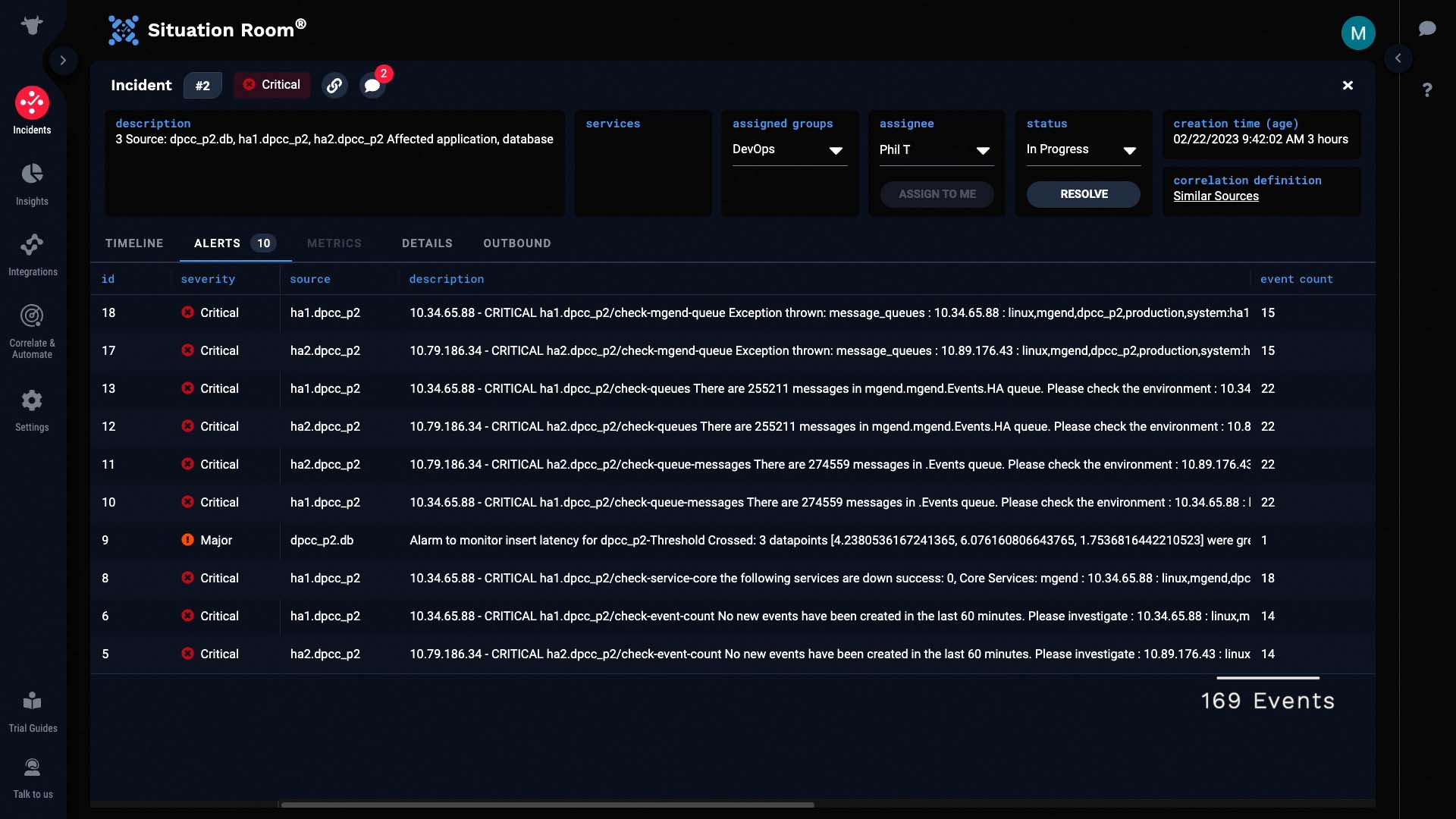
Lets see what else we can learn from the alert details. We can see that the dpcc system is the one involved.
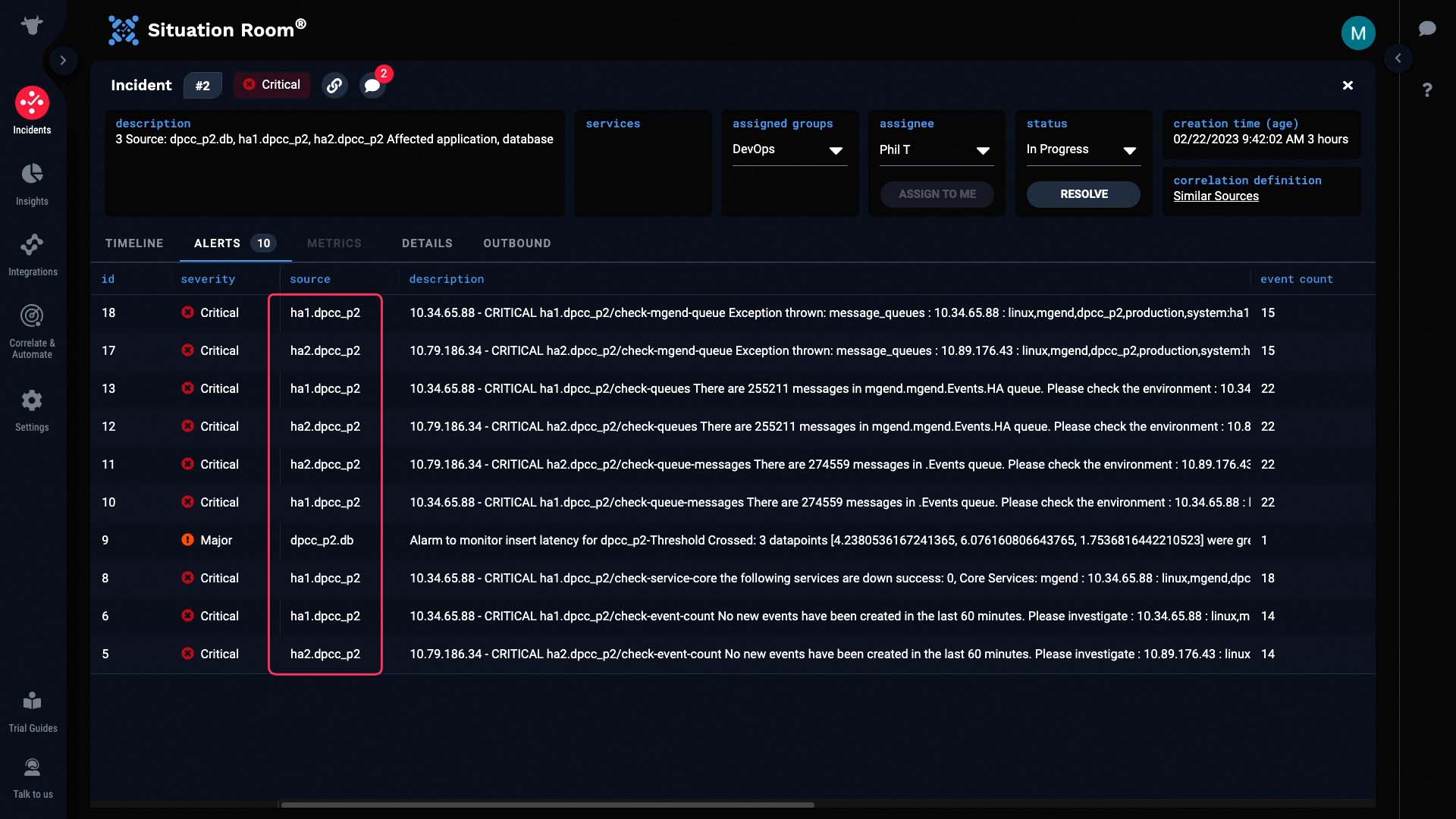
We have a monitoring setting to generate events when there is no activity for a prolonged amount of time. The hosts in this HA pair are not generating data...
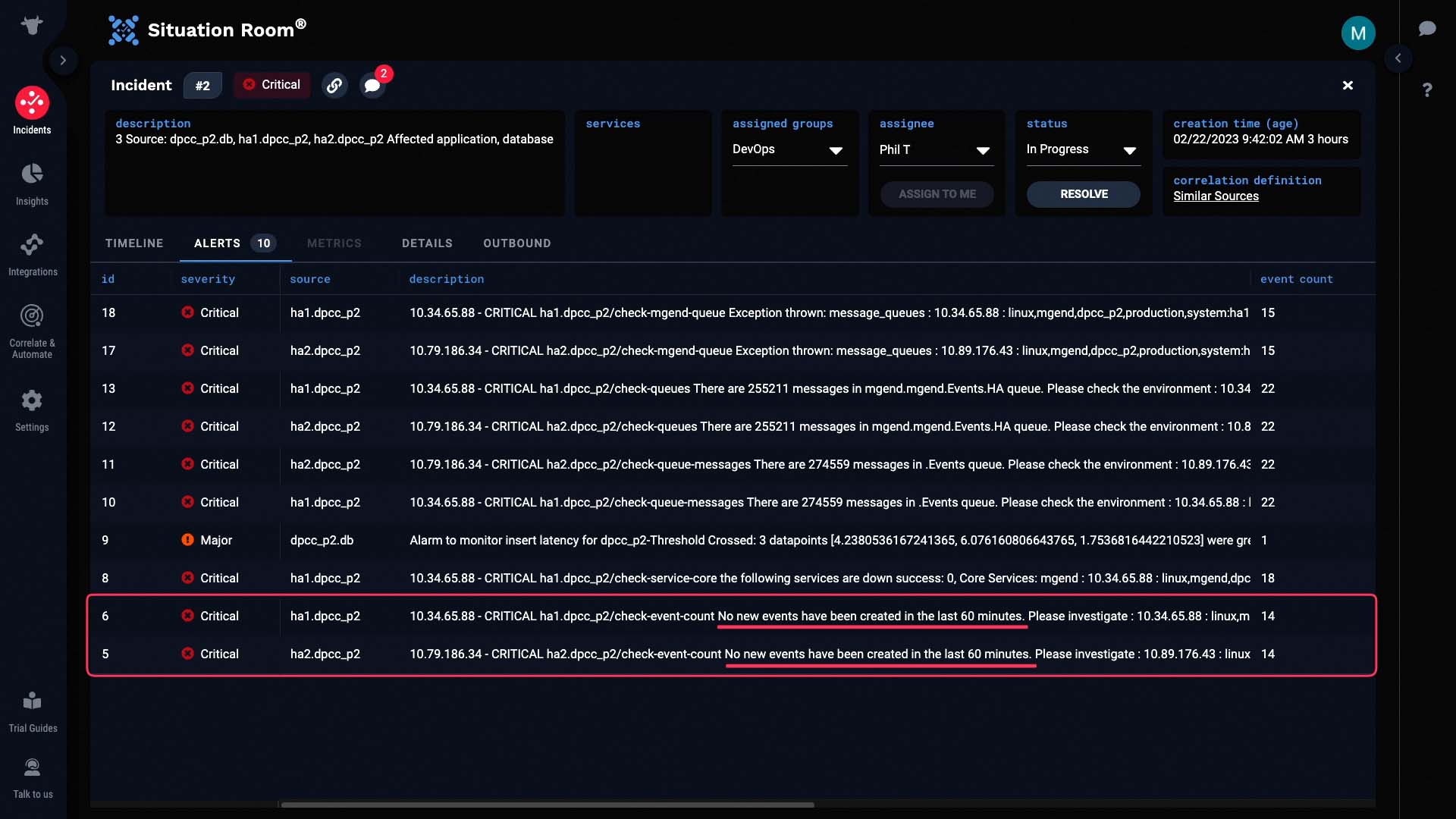
...and it looks like a core service is down.
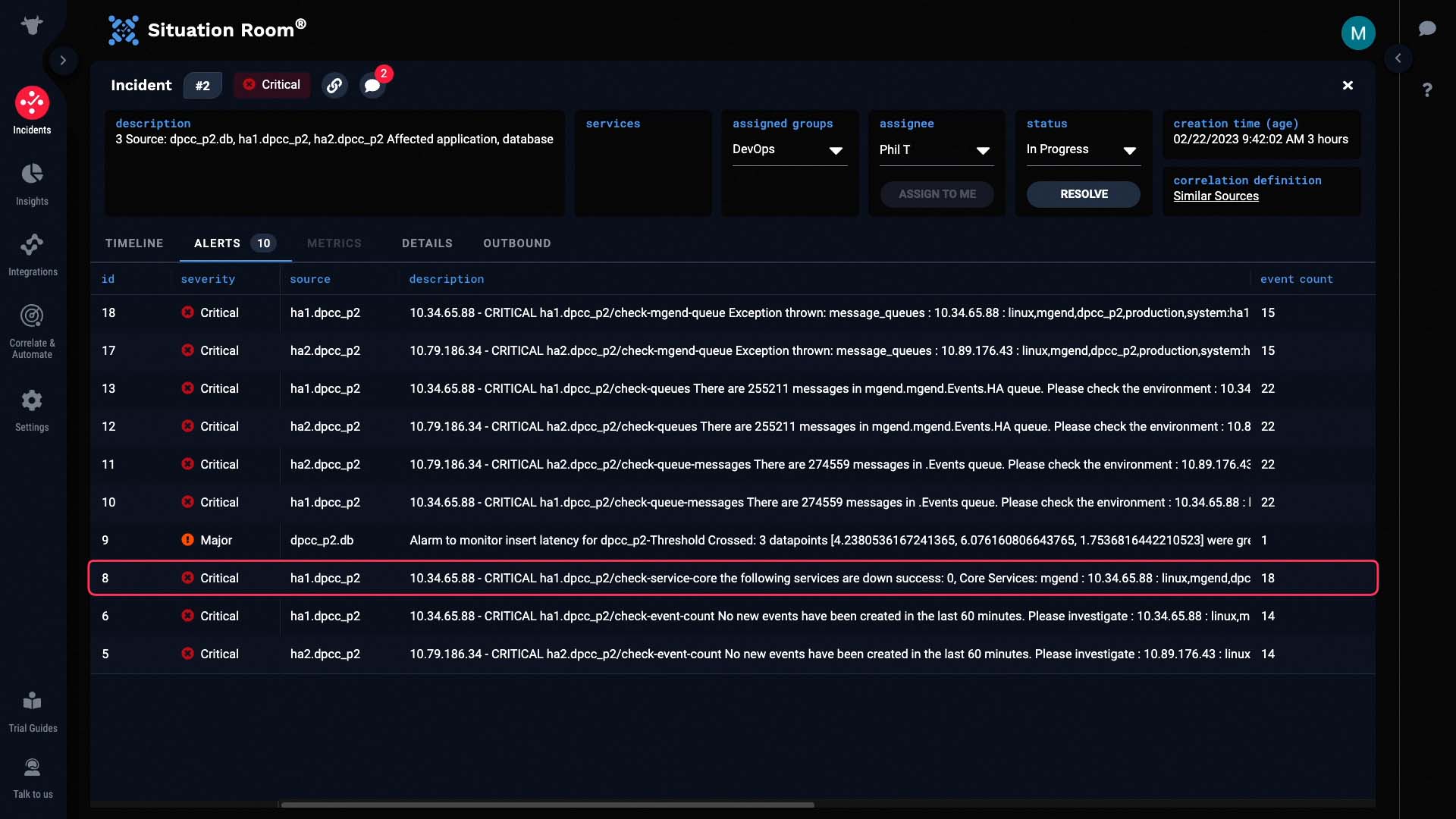
The internal message queues are backed up.
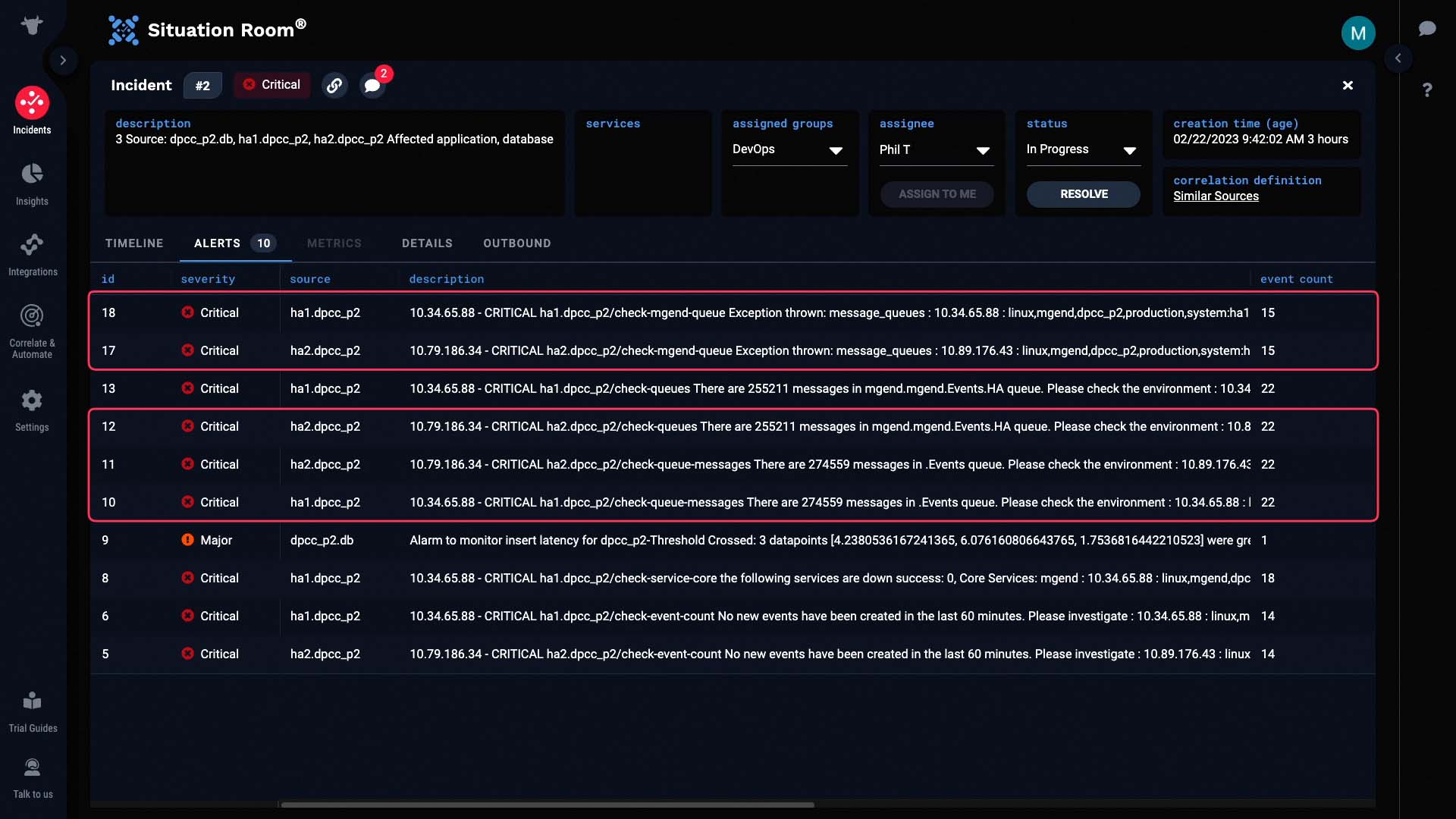
Looking here, it looks like we are having problems with slow database writes. It’s possible that database problems might have caused the core processing service to fail.
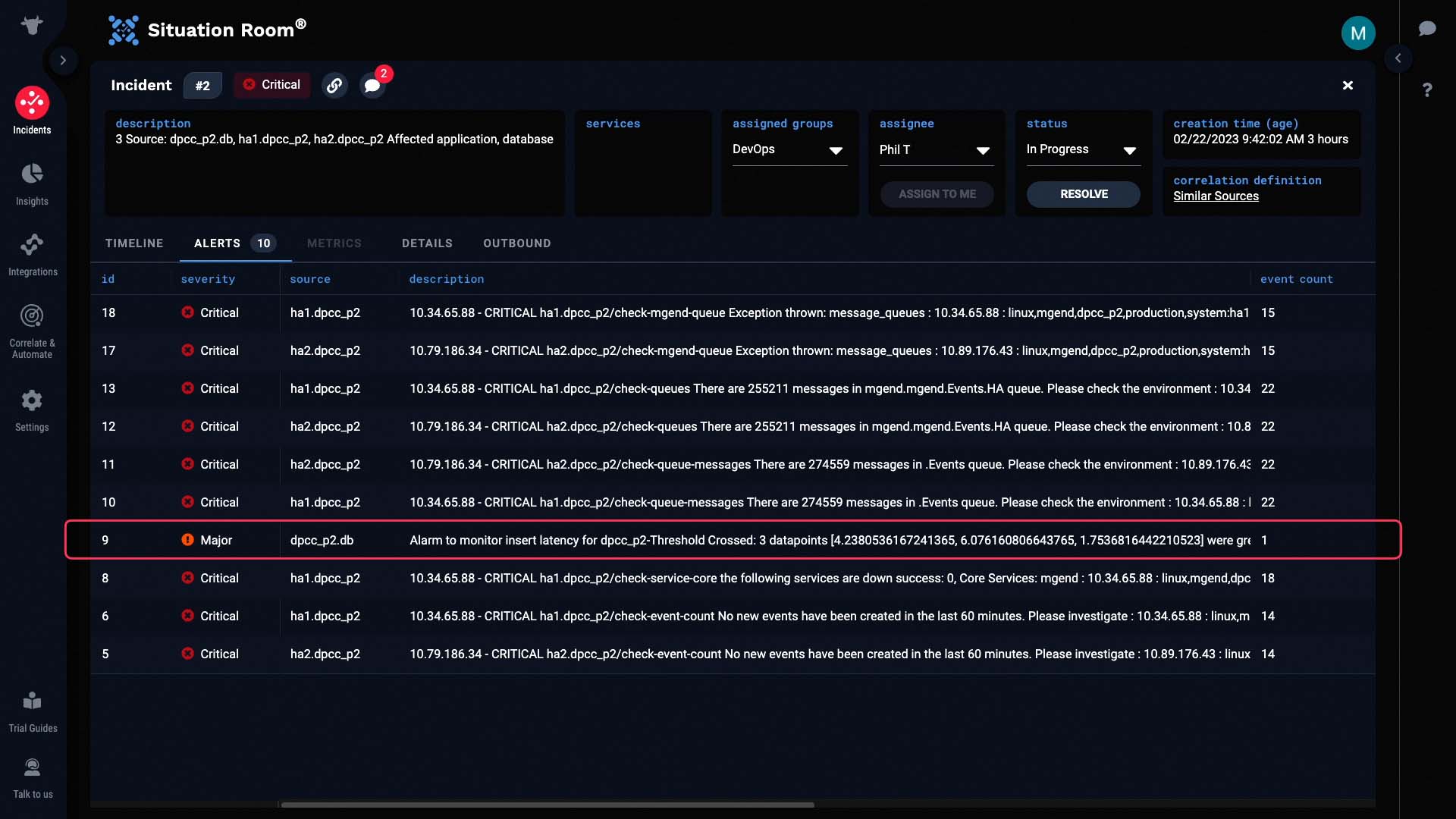
So, through Incident Management’s deduplication and correlation functionality, instead of looking at 1700 events to find 169 related events, you are presented with a complete picture from the start. Thanks for watching!