Syslog LAM
Syslog provides a way for network devices to send event messages to a logging server – usually known as a Syslog server. The Syslog protocol is supported by a wide range of devices and can be used to log different types of events. For example, a router might send messages about users logging on to console sessions, while a web-server might log access-denied events. This document describes the configuration required to establish a connection between the Syslog server and the Syslog LAM.
The workflow of gathering alarms from a Syslog server and publishing it to Moogsoft Onprem is outlined below:
Configure the LAM
The events received from a Syslog server are processed according to the configurations in thesyslog_lam.conf file. The processed alarms are published to Moogsoft Onprem.
The configuration file contains a JSON object. At the first layer of the object, LAM has a parameter called config, and the object that follows config has all the necessary information to control the LAM.
Monitor
The Syslog LAM fetches the events from the Syslog Server. You can configure parameters here to establish a connection with Syslog:
General
Field | Type | Description |
|---|---|---|
name and class | String | Reserved fields: do not change. Default values are Syslog Monitor and CSyslogMonitor. |
monitoring_type | String | This is the monitoring type. It can be either SOCKET or FILE. The SOCKET is used for establishing a TCP or UDP connection, while FILE is used for directly monitoring a log file. |
protocol_type | String | Enter the protocol type here. This field has to be entered if you have selected |
address | String | Enter the IP address of the server here. This field has to be entered here if you have selected |
port | Integer | Enter the port of the server here. This field has to be entered here if you have selected |
target | String | Enter the log file from which you want to recieve alerts. This field has to be entered here if you have selected |
load_at_start | Boolean | If this flag is set to |
exit_after_initial_load | Boolean | If set to |
event_ack_mode | String | The queued_for_processing: Event is acknowledged after it is added to the Moolet queue. event_processed: Event is acknowledged after it is processed in a Moolet queue. NoteIf you have not specified the mode in the |
Note
For monitoring_type set to FILE, it is mandatory to set load_at_start and exit_after_initial_load fields as true.
Example
Config File
monitor:
{
name : "Syslog Monitor",
class : "CSyslogMonitor",
monitoring_type : "SOCKET",
protocol_type : "UDP",
address : "localhost",
port : 514,
target : "bow.syslog.log",
load_at_start : true,
exit_after_initial_load : false,
event_ack_mode : "queued_for_processing"
},
Agent and Process Log
The Agent and Process Log sections allow you to configure the following properties:
name: Maps to
$Laminstancename, so that theagentfield indicates events Moogsoft Onprem ingests from this LAM.capture_log: Name and location of the LAM's capture log file, which it writes to for debugging purposes.
configuration_file: Name and location of the LAM's process log configuration file. See Configure Logging for more information.
Data Parsing
Any received data needs to be broken up into tokens. When you have the tokens, you can start assembling an event. The data received from a Syslog server or a Log file can be called as message. A typical BSD Syslog message has the following groups:
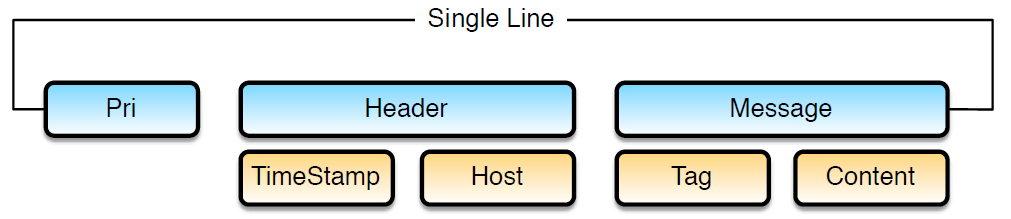 |
Pri: Pri is a combination of severity and facility.
Header: Header contains a combination of Timestamp and Host.
Message: The message contains the combination of Tag and content
Although BSD messages should contain these components, few rarely do. The PRI (severity and facility combination) is rarely used, with most messages starting with an RFC compliant timestamp. The LAM has to be configured in a way that it accommodates both BSD and near-BSD compliant messages (with and without the PRI). The implementation specific changes can be made in the regular expression used to determine a valid or invalid message.
Like BSD messages, the Syslog LAM can receive any type of Syslog message, e.g. kiwi, cisco, etc. For configuring the Syslog LAM, you should know the type of message received by the LAM and its regular expression. Some regular expressions for different types of Syslog messages are given in the parsing section of the configuration file. A new regular expression can be added to the parsing section, for this you must know the format of received message and its regular expression.
Syslog LAM supports multiple types of Syslog messages. After receiving the message, it is parsed one by one using all the regular expression present in the parsing section. If there is a match, then the parsed message is sent to the variable section. If the message does not match with any of the given regular expression, then it is parsed using the regular expression pattern_name: "default" in the parsing section. This captures the complete message and assigns it to a variable message in the variable section.
Note
For every regular expression of a Syslog message type in parsing, there should be a corresponding section in variables.
In the Parsing section, the tokenising of the received message is done using either a regex subgroup or delimiters. The tokenised messages can then be assigned in the variables section and forwarded to the lambot SyslogLam.js. The SyslogLam.js breaks the tokenised message and then assigns it to the respective Moogsoft Onprem fields and publishes the event to MooMS.
parsing:
[
{
pattern_name : "pattern1",
pattern : "(?mU)^((?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\\s+\\d{1,2}\\s(?:(?:\\d{2}:){2}\\d{2}))\\s((?:(?:[a-z0-9]+ (?:\\.|:|-|_)*){1,}))\\s(.*)$",
tokeniser_type: "delimiters",
action : "accept",
capture_group : 0,
delimiters :
{
ignoreQuotes: true,
stripQuotes : true,
ignores : "",
delimiter : ["||","\r"]
}
},
{
pattern_name : "pattern2",
pattern : "(?mU)^((?:<\\d{1,3}>)?)\\s*((?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\\s+\\d{1,2}\\s(?:(?:\\d{2}:){2}\\d{2}))\\s((?:(?:[a-z0-9]+(?:\\.|:|-|_)*){1,}))\\s(.*)$",
tokeniser_type: "regexp_subgroups",
action : "accept"
},
{
pattern_name : "pattern3",
pattern : "(?mU)^(?:\\[((?:Mon|Tue|Wed|Thu|Fri|Sat|Sun)\\s+(?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\\s+(?:\\d{1,2})\\s+(?:(?:[0-1]\\d|2[0-3]):(?:[0-5]\\d):(?:[0-5]\\d).(?:\\d{1,3}))\\s+(?:\\d{4}))\\])\\s*((?:[a-zA-Z0-9]+(?:\\.|-|_|\\[|\\]|\\(|\\))*){1,})\\:\\s+(.*)$",
tokeniser_type : "regexp_subgroups",
action : "reject"
}
],The fields which are configured in the parsing section are as follows:
pattern name: Enter the type of syslog message that is received by the LAM, e.g. Dell syslog.
pattern: The regular expression which will be matched with messages received from the server. The string which matches the regular expression is extracted from the message.
Regular expressions and their explanation is as follows:
/^((?:<\d{1,3}>)?)\s*((?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\s+\d{1,2}\s(?:(?:\d{2}:){2}\d{2}))\s((?:(?:[a-z0-9-]+(?:\.|:)*){1,}))\s(.*)$/
Expression
Description
^
The beginning of a line
((?:<\d{1,3}>)?)
Optionally followed by a “<” followed by between 1 and 3 digits followed by a “>”
\s*
Followed by 0 or more spaces
((?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)
Followed by one of Jan, Feb, Mar etc.
\s+
Followed by at least one space
\d{1,2}
Followed by one or two digits
\s
Followed by a single space
(?:(?:\d{2}:){2}\d{2}))
Followed by 2 digits followed by a “:” followed by 2 digits followed by a “:” followed by 2 digits (hh:mm:ss) Followed by a single space
\s
Followed by a single space
((?:(?:[a-‐z0-‐9-‐]+(?:\.|:)*){1,}))
Followed by something like an IP address (v4 or 6) or a host name (10.0.0.1, a:b:c:d, a.b.c.d)
\s
Followed by a space
(.*)$
Followed by anything up to the end of line
tokeniser_type: The 2 types of tokeniser used for tokenising are as follows:
regexp_subgroups: To tokenise based on regular expression subgroups, enter
regex_subgroupsin thetokeniser_typefield. This tokenising method tokenises the extracted string based on groups in a message. An expression in the parenthesis in the regular expression denotes a group. For example, the expression ((?:?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\\s+\\d{1,2}) is a group which contains the date and time.tokeniser: To tokenise based on delimiters, enter
delimitersin thetokeniser_typefield. The extracted string is tokenised based on the delimiters present in it.
action: This field is used for including or rejecting the matched regex text in the received event. If set to "
accept", then the matched regex text in event will be sent for further processing. If set to "reject", then the matched regex text will be rejected.capture_group: This is the group in the message that has to be extracted and further used in the variables section. For example, if "1" is given in this field, then group 1 of the message is only picked for tokenising. This field will be used when
delimitersare entered in the fieldtokeniser_type, and it can be commented forregexp_subgroups. You can usecapture_groupwhen only a particular group in the extracted string has to be tokenised.Note
If "0" is entered, then all the groups of the message will be picked for tokenising.
Note
In the Syslog LAM, parsing is done using the regular expression. For tokenising, you can use either
regexp_subgroupsordelimiters.
Example of the tokenisation using regexp_subgroups
The parser searches for strings as per the expression defined in the pattern field. The extracted string is then tokenised based on the configuration done in the variable section. The regular expressions for some of the syslog formats are defined above. If you have to define regular expressions of a different format, then you can define the regular expression in the parsing section. As an example you can see below a section for the regular expression parsing of events received from a Dell server:
{
pattern_name : "pattern4",
pattern : "(?m)^\\s*((?:<\\d{1,3}>)?)\\s*((?:(?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\\s+\\d{1,2})\\s+(?:(?:[0-1]\\d|2[0-3]): (?:[0-5]\\d):(?:[0-5]\\d)))\\s+((?:[a-zA-Z0-9]+(?:\\.|-|_|\\[|\\]|\\(|\\))*){1,})\\s+(.*)$",
tokeniser_type : "regexp_subgroups",
action : "accept"
}pattern_name: This is the name of the pattern.pattern: This is the regular expression which will be matched with messages received from the server, e.g. "(?m)^\\s*((?:<\\d{1,3}>)?)\\s*((?:(?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\\s+\\d{1,2})\\s+(?:(?:[0-1]\\d|2[0-3]):(?:[0-5]\\d):(?:[0-5]\\d)))\\s+((?:[a-zA-Z0-9]+(?:\\.|-|_|\\[|\\]|\\(|\\))*){1,})\\s+(.*)$".tokeniser_type: Theregexp_subgroupscaptures and then tokenises the message based on the regular expression given in the fieldpattern.
Example of the tokenisation using delimiters
Delimiters define how a line is split into tokens, also known as “tokenising”. For example, if you have a line of text data, it needs to be split up into a sequence of sub strings that are referenced by position from the start. So if you were processing a comma-separated file, where a comma separates each value, it would make sense to have the delimiter defined as a comma. Then the system would take all the text and break it up into tokens between the commas. The tokens could then be referenced by position number in the string starting from one, not zero.
For example, if the input string was “the,cat,sat,on,the,mat” and comma was used as a separator, then token 1 will be “the”, token 2 will be “cat” and so on.
There are complications when it comes to tokenisation and parsing. For example, if you say comma is the delimiter, and the token contains a comma, you will end up with that token containing a comma to be split into 2 tokens. To avoid this, it is recommended that you quote strings. You must allow the system to know whether it should strip or ignore quotes, and therefore, the stripQuotes and ignoreQuotes parameters will be used. Below is an example of parsing using delimiters for syslog messages received from a CISCO device:
{
pattern_name : "pattern2",
tokeniser_type : "delimiters",
capture_group : 1,
delimiters :
{
ignoreQuotes: true,
stripQuotes : true,
ignores : "",
delimiter : ["||","\r"]
}
}
The above example specifies:
pattern_name: This is the name of the pattern.tokeniser_type: To use delimiters for parsing, enterdelimitersin this field.capture_group: This is the group in the message that has to be extracted and further used in thevariablessection. For example, if "1" is given in this field, then group 1 of the Syslog message will only be picked for tokenising.Note
If "0" is entered in the
capture_groupfield, then all the groups of the message will be picked for tokenising.ignoreQuotes:For strings that are quoted between delimiters, setignoreQuotestotrue, the LAM will look for delimiters inside the quote. For example, <delimiter>”hello “inside quote” goodbye”<delimiter> gives a token [hello inside quote goodbye].stripQuotes: If set totrue, it will remove start and end quotes from tokens. For example, “hello world” gives a token [hello world].ignores:This field contains a list of characters to ignore. Ignored characters will never be included in tokens.
delimiter: This field contains the list of valid delimiters used to split strings into tokens. Here || and the end line character are the defined delimiters.
Note
If an empty string is mentioned in the delimiter field, then no LAM tokenisation will be done, instead the entire message will be taken into a single token.
Note
If the message does not match any regular expression given in the parsing section, then the LAM automatically sends the received message as a single line text to SyslogLam.js. The message is tokenised and sent to Moogsoft Onprem by the SyslogLam.js.
Also if you don't know a regular expression that can be used for tokenisation, then you can leave the parsing and variables section blank. The received message by the LAM will be then sent to SyslogLam.js as a single line text.
SyslogLam.js
The filter defines whether Moogsoft Onprem uses a LamBot. If the presend value is commented, then no filter is applied to the events produced and all events will be sent unchanged to the MooMS bus. If a LamBot is defined, then the event is passed to the LamBot. The Syslog LAM uses the lambot syslogLam.js.
filter:
{
modules: [
"RegExpUtil.js",
"SyslogUtil.js",
"SyslogEvents.js",
"LamUtility.js"
],
presend: "SyslogLam.js"
}
In the above example, the presend is set to "SyslogLam.js" which is the Syslog lambot that extracts the values from the tokenised message and after assembling the values, publishes the events to MooMS.
The modules defined in the modules section are used by SyslogLam.js to extract values. In the above example, the following modules are defined:
RegExpUtil.js: A module holding common regular expressions and regular expression related functions (search and replace).SyslogUtil.js: A syslog specific module, defining a “message” object and instance methods, and other methods used in the lambot.SyslogEvents.js: A library of actions to take for specific events, based on an EventId. Message actions are defined by functions – so a single function can cover many message types.LamUtility.js: Contains functions that are repeatedly used in a lambot (date, debug etc.).
Note
You can edit the SyslogLam.js to process specific Syslog messages. The lambot and the modules can be found in the $MOOG_HOME/bots/lambots directory.
The workflow of syslog lambot is as follows:
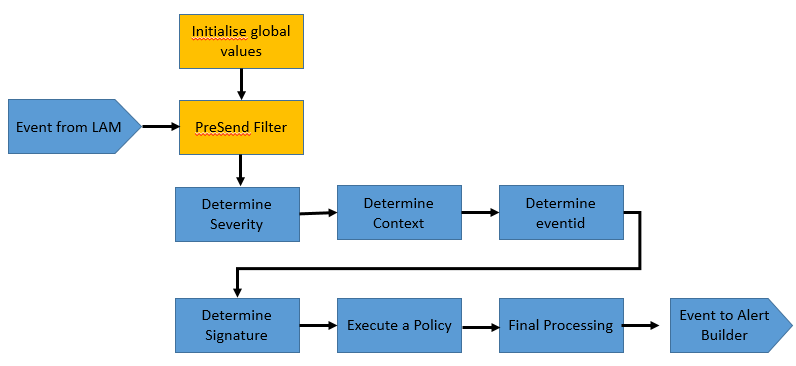
Determine Severity: Associate one of the standard Moogsoft severities with the event.
Determine Context: Determines the entities about this event, such as host, interfaces, ports etc.
Determine Eventid: Determines the event id of the event.
Determine Signature: Create a valid Moogsoft Onprem signature that will allow effective de-duplication for the events.
Execute a policy: This will execute a message having an optional specific behavior associated with it (e.g. message transformation).
Final Processing: Allow any last stage processing before the event is dispatched (filtering etc.).