Situation Design Maintenance
Your monitored environment and business practices are constantly evolving. With that, your alert clustering settings need to change also. In this section, we will discuss what you can do to detect changes and update your clustering logic.
Ensure All Important Alerts Become Situations


You may have produced a perfect Situation design for a given environment. But the environment and the requirements change every day in the busy ITOps world. With the changes, your entropy threshold may become obsolete, and as a result, your Entropy filter may block out an important alert from becoming a Situation. If the operators do not want to miss these alerts with low entropy values, you can forward them to a separate ‘low entropy alerts’ Cookbook. For example, you could cluster these alerts into Situations based on the same hostname. Ask the teams to examine the content of these Situations periodically to make sure nothing important has been missed. If an operator identifies a loose alert that is of low entropy but actually should have been part of a Situation, whether on its own or part of a wider Situation, then a few things can be done:
You could create a specific Cookbook Recipe just for that alert type. Having a single alert Situation is a valid use case.
Look at lowering the entropy threshold for that particular event stream.
Create a list of priority words that will bias the entropy of the corresponding alerts. Events containing a word in the priority words list will always be given an entropy value of 1. So priority words should be chosen with care - they should be very uncommon; a widely used word will bump up the entropy for all alerts containing that word.
This is also a good way to validate your Situation design after the initial configuration. During the tuning phase, check if any of the loose alerts (alerts that have not been clustered into any Situations) should actually be creating Situations on their own or be part of existing Situations created at the time.
Avoid Aged Situations Crowding the Workspace


If Situations are not actioned and are left open with no intent to ever being closed, your system might end up being overrun with aged situations still in an open state. This is not only distracting for the operators but also have memory performance implications any active situations are still being retained in memory for Merge and Resolve activities. For alerts, keeping them open means those alerts would never get the chance to renew their enrichment.
You can set up an Auto-close on unworked alerts and Situations of a certain age to avoid such problems.
Handle Overly Noisy Alerts of High Count
Very hight count alerts impact the performance when data is being moved from active to the historic database due to database split. Implement an auto close in the AlertRulesEngine, so when an overly noisy alert goes beyond a certain count limit they can be closed automatically.
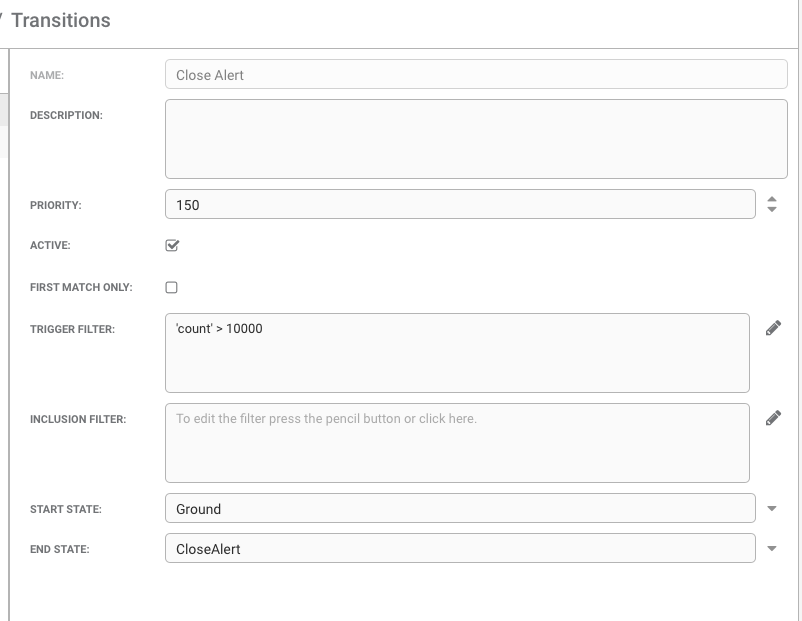
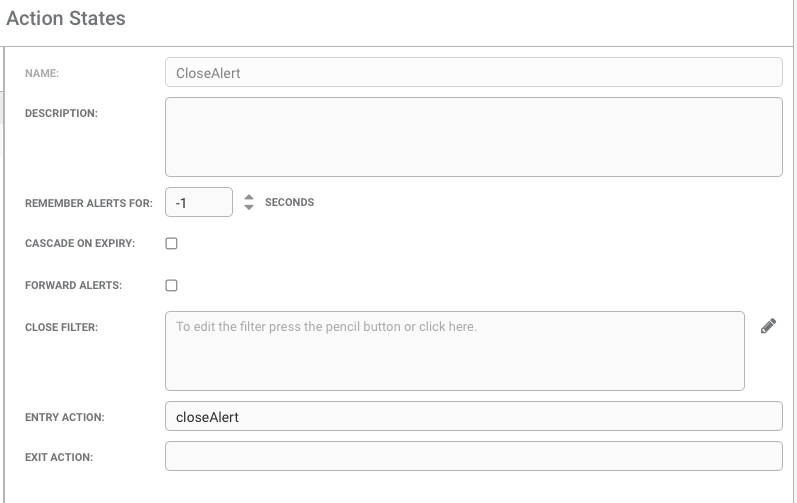
See below for a sample set up in the AlertRulesEngine. In this case, alerts with a count higher than 10000 are being transitioned to the CloseAlert state. Once the alert enters the state it is processed by the closeAlert function in ARE.
The benefit of using ARE instead of the usual Auto-Close rule is because the later requires the alert to be older than a certain period (minimum 5 minutes given the task run) while the ARE closes the alert instantly once it reaches the count limit.
Note
This function will only close alerts that are not part of any active Situations.
In AlertRulesEngine.js:
.....
// function in ARE to close an alert that is not part of any active Situations
function closeAlert(alert,associated){
var alert_id=alert.value("alert_id");
if (alert.value("active_sig_list").length === 0 ) {
var closed_flag=moogdb.closeAlert(alert_id);
if (closed_flag) {
logger.debug("Alert closed by ARE. Alert_id: " + alert_id);
} else {
logger.warning("closeAlert: Alert failed to close by ARE. Alert_id: " + alert_id);
}
} else {
alert.forward(this);
}
}