LAM and LAMbot Ingestion
LAMs are groups of processes which ingest event data for a third party vendor. You configure LAMs as a more complex alternative to monitoring integrations in Moogsoft Enterprise, enabling you to configure properties which are unavailable in the integrations UI, such as high availability.
You configure LAM event ingestion settings in two places:
LAMs (
lam.confconfiguration files): A set of components that receive and normalize data that flow into the Configure Alert Builder Moolet. Handles data acquisition, tokenization, and mapping. In some cases, LAMs can also perform some normalization.LAMbots: Optional JavaScript within LAMs to handle additional transformation processes.
LAMs
In some cases you can use separate mechanisms to ingest the same data, for which receiving LAMs are typically preferable over polling LAMs.
When you have multiple LAM ingestion options to choose from, Moogsoft Enterprise recommends you consider these LAMs, in the following order of preference:
REST LAM or webhook:
As a direct forward from the underlying monitoring tool, or via a messaging bus such as RabbitMQ, Kafka, JMS.
Provides a more reliable delivery mechanism, and unlike polling LAMs, has no dependency on a polling cycle.
REST Client LAM
SNMP LAM if MIB conversion already exists.
Socket LAM if event raw payload is structured to allow tokenisation.
Syslog LAM if messages are structured and invariable and require little or no ongoing maintenance via email.
UDP Socket and SNMP protocols do not offer guaranteed delivery of forwarded events as opposed to webhook or messaging bus mechanisms.
Note
If you swap the ingestion mechanisms, for example swap webhook with a RabbitMQ LAM for a monitoring system, make sure you use a consistent approach to the data parsing in the LAMbot to avoid any impact to downstream processing.
LAM types
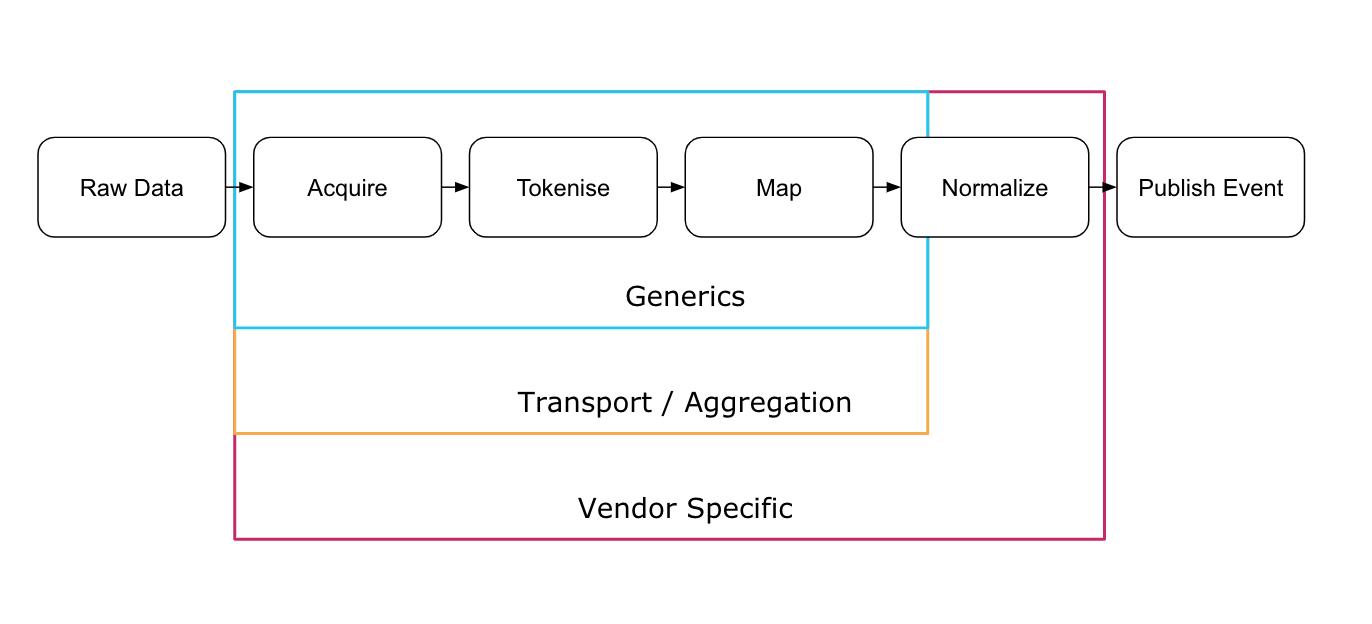
The configuration process for each LAM falls under one of three categories: Generic, Aggregation, and Vendor-specific. Each requires a different degree of configuration.
Generic LAMs
The generic adapters have no specific default configuration, which enables you to customize them to any suitable single data source that sends events on the supported protocol. The associated config and LAMbot files provide only a framework for acquiring, tokenizing, and mapping the raw data, and require that you configure the logic for normalization, including an appropriate signature.
There are three types of generic LAMs:
Socket: Accepts data over TCP or UDP network socket, and lets you specify how to parse the incoming data stream.
Rest/webhook: Listens for data in JSON format over a REST protocol.
Rest Client: Polls a REST server and accepts JSON data.
Aggregation LAMs
The aggregation LAMs are specific to a protocol or vendor platform. They contain a configuration and a LAMbot for generically consuming events from these sources, but perform little to no processing of the event contents themselves. Like generic LAMs, aggregation LAMs require you to configure normalization.
Since these are often aggregated event sources, a single ingestion source may contain multiple event formats. For example, if a customer sends all of their event data, which contains events from both Netcool and Nagios, to a Kafka bus. When the Kafka LAM consumes the data they still remain Netcool and Nagios events, and therefore contain different attributes and lifecycle behavior. To make them consistent, the event data requires mapping, routing, processing, and normalization. Without normalization at the aggregation layer, you must configure all of these in the LAMbot.
Another example of aggregated ingestion is how the Splunk consumes the syslog data that arrives from the Splunk platform. In this case, you must configure the Splunk LAM to construct an appropriate signature and syslog string parsing into attributes, such as hostname and severity, unless the aggregation layer already performs this.
The most challenging part of setting up an aggregation LAM is identifying the different event formats and assessing the normalization workload that each requires. You may need to add routing logic to handle separate formats. Use centrally administered modules to overcome and compensate for complexity within the LAMbot.
The aggregation LAMs are:
Logfile
Email
Kafka
JDBC
Splunk
Syslog (UDP or TCP socket)
Trapd (UDP)
RabbitMQ
WebSphere MQ
Vendor-specific LAMs
Vendor-specific LAMs are the most complete, because they are product-specific with the data in a known format, and manageable in a consistent manner regardless of customer. This type of LAM only requires light customization to the default configuration and, if necessary, to the LAMbot.
See Integrations and LAMs for the complete list of vendor-specific LAMs.
LAMbots
LAMbots are customizable JavaScript files which perform further processing after a LAM has acquired and parsed raw data. They are technically optional, but you do need to use them to perform data normalization.
Some examples of normalization you perform using LAMbots are as follows:
Preset a
custom_infoobject common to all ingested data and across all enabled LAMs.Extract the severity value from the event message string in case there is no corresponding field to map from directly.
Sanitize the event message and truncate it if it is too long.
Derive the alert classification, for example, an "availability" or "performance" type of alert.
Decompose the hostname string if it has an associated naming convention that embeds information such as location or server functionality (useful for alert clustering).
See LAMbot configuration for more information.
Additional Resources
Review the video Introduction to LAMbots [15 min]