Hold a Discovery Session with Operators
The first step of Situation design is to identify the operators' needs. Identify the teams that will be onboarded to Moogsoft Enterprise, and audit the operators within the teams about the information they need to see in Situations and the corresponding operational workflow.
Your goal for the discovery session is to identify the content and context, as well as primary and secondary data required to produce the result. Also, by investing your time in understanding exactly what information is required to respond to incoming events, you will be able to perform with clear purposes, which in turn reduces the likelihood of impairing system performance with unnecessary enrichment queries.
Who Should I audit?
DO
Speak to the operators or SMEs who understand the alert content and will be directly involved in working on Situations in Moogsoft Enterprise.
DO NOT
Don't interview system administrators. This is a typical mistake at this stage. The team members responsible for maintaining Moogsoft Enterprise typically can't articulate the information operators will need to resolve Situations.
Tip
The operators you audit at this stage are not likely to understand Moogsoft Enterprise yet. This is perfectly fine. As long as they understand the high-level concepts of what an alert and a Situation are in Moogsoft Enterprise, they will be able to provide the input you need.
Goal: Discover the Content and Context Required
The goal of the discovery session is ultimately to identify the content and context necessary to design Situations.
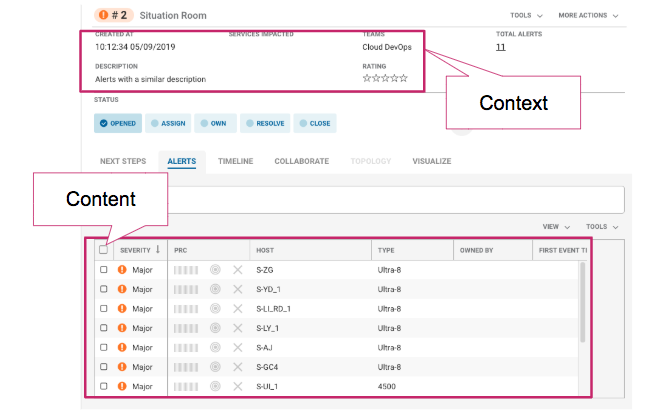
A Situation has associated content and context. The content is the list of alerts shown in a Situation, while the context is the interpretation of that list of alerts. For the example below, the content of the Situation is the 11 alerts of the same severity. The Situation was assembled in response to the contextual need of the organization. They want to bundle the alerts with a similar description, with a Major severity level and assign them to the Cloud DevOps team.
Step 1: Identify the Organizational Context
Start with identifying the organizational context. What teams will use Moogsoft Enterprise? And how should alerts be routed to different teams? Answers to these questions can provide you with the big picture requirements.
For example, where are their servers located? How distributed are they? Do they have edge locations?
What is the scope Moogsoft Enterprise is expected to handle? If they want to feed the monitoring data from both dev and production, then it is likely that you want to cluster alerts separately for each environment. In this way, by learning the organizational context you learn the clustering requirements.
Also, learning where the organization is on the journey to transform its ITOps practices should inform you what level of implementation will be most successful. For example, an organization may want to keep their existing workflow and only introduce Moogsoft Enterprise as a system for noise reduction. In that case you can focus your discovery sessions on identifying which alerts matter and which ones the operators consider to be noise.
Consult this video to learn about the adoption stages and identify the proper context Moogsoft Enterprise can fit in at a given organization.
Moogsoft Enterprise Adoption Guide [25 min]
Step 2: Identify Team and Individual Needs
After identifying the overarching context, move on to the teams' and operators' needs. What will help the operators perform their tasks better? What are they hoping to achieve with Moogsoft Enterprise? Do they want to view items that go wrong simultaneously at the same location? Or would they rather receive notifications when the infrastructure components underlying a specific business service fail? Answers to these inquiries lead you to identify the context you want to use to cluster alerts.
For example, if your operations teams are organized around applications, they are interested in seeing alerts clustered on the intersections of an impacted application. In this case, the context of a Situation is "alerts that are affecting the same application". A Situation that says "here are the list of broken items that are impacting the application you are responsible for" nicely aligns with this workflow.
But what if applications are not granular enough for your organization? If you need to organize the alerts around the impacted services, Situations need a different context: "here is the list of broken items that are impacting the service you are responsible for". So learning the specific context your organization's needs is critical for successful Situation design.
Along with interviewing, it often helps to sit down with your operators and observe how they work. Ask them questions on specific ways they handled the event at hand. Even if they struggle to articulate their needs in an abstract sense, they can often explain what is going on and what they need to resolve the case at hand. Your observation will provide a blueprint for the higher-level clustering pattern.
Tip
While Situations are organized around one context, an alert can have multiple contexts. As a result, it can belong to multiple Situations. For example, an alert can be grouped together with other alerts that are impacting the same network, but also the same alert can belong to a Situation that is organized by the floor location of the rack. An alert can be represented within both the microscopic view like an application failure and the macroscopic view like a datacenter failure.
Consider the Situation Labelling Strategy
Situation descriptions are one of the primary means that operators use to find and identify relevant Situations. For this reason, you should carefully consider the alert content to include in your descriptions. For example, imagine you have multiple separate Situations that impact separate environments occurring at the same time. How does an operator prioritize and distinguish these if the description does not include the environment, such as Test, Production, or UAT, where the Situation occurred?
Good descriptions can also help operators diagnose and assign Situations. Suppose a team assignment depends on the physical location where the Situation occurred. If the description includes the location, an operator can quickly assign a Situation to the correct team.
Consider how you might label the Situations and ask clarifying questions during the discovery sessions. The criteria for defining "good" descriptions, like the criteria for "good" data and "good" Situation design, is highly dependent on the specific needs of your organization and operators. Always consult with your operators and users when planning and maintaining your deployments.
Identify Primary and Secondary Data
Along with content and context, use operator audits to identify primary and secondary data requirements.
Primary workflow data is the information required to correlate alerts and label Situations. Identifying primary data helps you design Situations. Secondary workflow data is the information that supports diagnostic activities such as ticketing and team assignment. Identifying secondary workflow data helps you identify the enrichment requirements, which in turn helps Situation design.
Ask operators what context they want to see presented within Situations. They may want to see items that go wrong together at the same location, or they may want to be notified when things that enable a business service to fail.
To help, look into past incidents and identify what manual correlation the operator had to do in order to relate the events describing the incident. Is that information available within the event payload itself or available somewhere externally? If externally, you want to know if the data is accessible so you can use it to enrich the events in Moogsoft Enterprise.